
CLR Via C#个人笔记6 - 核心机制
大章20:异常和状态管理
异常处理机制
什么是“异常”
首先对异常有一个基本理解,对于一些预想外的情况(比如中途转换失败),需要对既有代码进行进一步的安全性保证,就需要由对异常的处理。
平时代码throw抛出就会结束后续代码的执行,终止进程,但是如果在try里throw就会被catch接住,执行catch内代码;如果catch也抛出但被更上层的catch抓住了,抛出地点的后续代码就不会执行了,但仍然会执行对应finally内的代码,之后finally结束后的代码不会执行。
异常处理标准流程
1 | private void SomeMethod() { |
try块
介绍略了。
对于程序设计时,多少代码放到try块中是很难把控的,应该根据catch和finally的对应处理来思考这个问题:
- 一段代码,catch后的挽回处理如果各不相同,那就该考虑多分几块
try{}catch(){}了 - 一段代码,他们的finally清理代码如果都不相同,那就不应该放在一起
catch块⭐
先说下捕捉类型,就是catch()括号里的玩意。C#要求捕捉类型必须是System.Exception以及它的派生类。当你括号里不指定时,就相当于捕捉System.Exception这个类型了,不过这样也没法在后续代码块里访问到异常信息了。
再说下关键,catch抓取错误的机制,也就是整个异常处理的机制。
- try中代码抛出异常后,CLR将搜索捕捉类型与抛出异常相同(或是其基类)的catch块。
- 如果catch没有任何捕捉类型与抛出的异常匹配,CLR会去回溯查找调用堆栈更高的一层的catch捕捉类型。
- 直到找到调用堆栈的顶部,仍然没有找到匹配的catch块,就会发生未处理的异常,这个后面讨论。
- 一旦CLR找到匹配的catch块,就会执行内层所有finally块中的代码,也就是 从抛出异常的try块-到匹配到异常的catch块之间 所有的finally块。顺序是:内层finally块 => 抓取到异常的catch块 => 抓取到异常的catch块的finally块 => …。
然后再说下catch到后,常用的catch块末尾处理选择,提供3种:
- 重新抛出相同的异常,向调用栈高一层的代码通知异常的发生。
- 抛出一个不同的异常,向调用栈高一层的代码通知异常的发生。
- 啥也不抛,正常从线程底部退出。
当选择3,线程从catch块的底部退出后,它将立即执行包含在finally块中的代码。如果没有,就执行catch块结束的后续代码。
1 | void Main(string[] args) |
最后,再说一下捕捉到异常时,会有一个变量将引用抛出的System.Exception对象:catch (Exception e)。可以用这个变量打印出堆栈调用。
finally块
包裹的是确保会执行的代码。
前面粉字里也说过,即使catch里也抛出了错误,仍然会执行finally内的代码。
除了Win32的TerminateThread杀死线程,或者TerminateProcess或System.Environment的FailFast方法杀死进程,finally块就不会执行。
非CLS异常
RuntimeWrappedException类
上面说的都是CLS标准的异常(也就是继承于Exception类的),但是也存在C#调用了其他编程语言写的方法,而且那个方法抛出了一个非CLS相容的异常,那么C#代码根本不能捕捉这个异常,从而造成安全隐患。
于是微软引入了全新的System.Runtime.CompilerServices的RuntimeWrappedException类,该类派生自Exception,所以他本身与CLR相容。当非CLS相容的异常被抛出时,CLR会自动构造这个类,并初始化+引用实际抛出的异常。也就是完成了 非CLS标准异常 => CLS标准异常。
Exception.StackTrace属性
异常抛出
其实CLR可以让异常抛出任何类型的实例,String、Int32都行。但是为了能够简化使用,协定为统一使用System.Exception类。
Exception.StackTrace属性
Exception包含几个公共属性:String Message、IDictionary Data、String Source、String StackTrace、MethodBase TargetSite、String HelpLink、Exception InnerException、Int32 HResult。
讲一下其只读的StackTrace属性,它指出异常发生前调用了哪些方法。
新构造Exception类时,StackTrace是null。
StackTrace的捕捉范围
抛出异常时,CLR会重置异常起点,所以CLR只能记录最新的异常对象的抛出位置。
比如catch中又抛出了异常throw e;,那么StackTrace捕捉的起始点就又更新了,前面抛出的堆栈抓不到了,只能抓到最底一层的。
最后生成一个字符串来指出从异常抛出位置到异常捕捉位置的所有方法。
System.Diagnostics.StackTrace类型
该类型定义了一些属性和方法,允许开发人员程序化地处理堆栈跟踪以及构成堆栈跟踪的栈帧。
用这个类型来自己定制一套堆栈记录机制,实现抓取到多层抛错的堆栈记录。
定义自己的异常类
设计原则
创建自定义异常类应严格遵循几个原则
- 声明可序列化(用于进行序列化写入,当然如果你不需要序列化。那么可以不声明为可序列化的)
- 添加一个默认的构造函数
- 添加包含message的构造函数
- 添加一个包含message,及内部异常类型参数的构造函数
- 添加一个序列化信息相关参数的构造函数.
- 可以把序列化重新继承ISerializable接口,重写序列化反序列化的方法
简单实践
1 | [] //声明为可序列化的 因为要写入文件中 |
书中的泛型Exception示例
比较复杂,就贴上图看一下。

设计范式
善用finally
1 | private void SomeMethod() |
C#自动实现finally
为了方便程序员,只要使用了lock、using、foreach语句和析构器时,C#编译器就会自动生成try/finally块代码,如下:
- 使用lock语句时,锁在finally块中释放。
- 使用using语句时,在finally块中调用对象的Dispose方法。
- 使用foreach语句时,在finally块中调用IEnumerator对象的Dispose方法。
- 定义析构器方法时,在finally块中调用基类的Finalize方法。
比如下面这个方法的实现,和上面的代码编译结果一样。
1 | // 这个方法的实现和上面的代码编译结果一样 |
备份、回滚状态
对于一些目前无法掌控到的异常,想要修复会无从下手。可以考虑一下下面的状态回滚:
1 | private void SomeMethod(int num) |
包装抛错
有的时候接受到了抛错,提前协定好,可以向外抛出不一样的错误类型。
因为直接让别人用你自己的包装类方法,如果抛错了,可能预料不到,抓不到错;如果提前协定好某些情况固定抛什么Exception,那么其他开发者就能提前预知要去抓这些错了。
1 | internal sealed class PhoneBook { |
未处理的异常
未处理异常的处理
异常抛出时,CLR在调用栈中向上查找与抛出的异常对象的类型匹配的catch块。如果没有任何catch块匹配抛出的异常类型,就发生一个未处理的异常,CLR一旦检测到有未处理的异常的存在,就会终止进程。
CLR的默认策略时将未处理的异常,写进Windows事件日志。
Windows事件日志
上述的未处理异常,在“事件查看器>Windows日志>应用程序”中可以看到,我个人推荐直接WIN+R运行eventvwr.msc。
对异常进行调试
VS 调试>异常
讲的是VS的菜单 “调试”>“异常”,能打开CLR和自己定义的所有能被识别的Exception类型,并可以选择在抛出某Exception时中断(本来的话要异常未处理才会中断)。
这个用到了直接百度吧,知道有这个功能就行。
约束执行区域 CER
PrepareConstrainedRegions
1 | private static void Demo1() { |
像上述这样的代码执行顺序,不难看出,finally里的错误就抓不住了,而且中间出错影响finally块代码执行。
我们想实现除非保证catch和finally块内的代码得到执行,否则就不执行try块中的代码。可以使用PrepareConstrainedRegions方法,JIT编译器如果发现在一个try块之前调用了这个方法,就会提前编译与try块关联的catch和finally块中的代码。JIT编译器会加载任何程序集,创建任何类型对象,调用任何静态构造器,并对任何方法进行JIT编译。如果其中任何操作造成异常,这个异常会在线程进入try块之前发生。
此外,JIT编译器提前准备方法时,还会遍历整个调用图,寻找应用了ReliabilityConstractAttribute特性的方法,提前准备这些被调用的方法。
1 | private static void Demo2() { |
ReliabilityConstractAttribute
聊一下这个属性,前面提到了,这个属性要配合PrepareConstrainedRegions方法使用。这样JIT编译器提前准备方法时,会遍历整个调用图,寻找应用了ReliabilityConstractAttribute特性的方法,提前准备这些被调用的方法。
首先会对这个属性实例传递一个枚举成员 Consistency:
| 枚举成员 | value | 详细 |
|---|---|---|
| MayCorruptAppDomain | 1 | 在遇到异常情况时,公共语言运行时 (CLR) 对当前应用程序域中的状态一致性不做任何保证。 |
| MayCorruptInstance | 2 | 在遇到异常情况时,此方法保证将状态损坏限制到当前实例。 |
| MayCorruptProcess | 0 | 在遇到异常情况时,CLR 对状态一致性不做任何保证;即这种情况可能损坏进程。 |
| WillNotCorruptState | 3 | 在遇到异常情况时,此方法保证不损坏状态。 (不保证此方法永远不会失效;但确实可以保证此类故障将永远不损坏状态。) |
以及枚举成员 Cer:
| 枚举成员 | value | 详细 |
|---|---|---|
| MayFail | 1 | 在遇到异常情况时,此方法可能会失败。 在这种情况下,此方法将向调用方法报告它是否成功。 该方法的方法体周围必须有 CER 以确保它可以报告返回值。 |
| None | 0 | 方法、类型或程序集没有 CER 的概念。 它不利用 CER 保证。 |
| Success | 2 | 在遇到异常情况时,保证此方法获得成功。 应始终在调用的方法周围构造 CER,即使是在非 CER 区域内调用该方法。 如果方法完成了其任务,则该方法成功。 例如,用 ReliabilityContractAttribute(Cer.Success)意味着当它在 CER 下运行时,它始终返回 ArrayList 中的元素的数目计数,并且它永远不能将内部的字段保留为不确定状态。 |
TODO
我说实话这节没有看懂,主要问题是不理解AppDomain的“状态”到底指的是什么,书中说22章会讲。以后在这里补吧。
代码协定
是什么
代码协定的核心是静态类System.Diagnostics.Contracts.Contract。
协定采取的形式:
- 前条件:一般用于对实参进行验证。
- 后条件:方法因为一次普通的返回或抛出异常而终止时,对状态进行验证。
- 对象不变性(Object Invariant):在对象的整个生命期内,确保对象的字段的良好状态。
怎么用
下面举个例子:
1 | public sealed class Item { } |
原理
有空看看吧,这个技术太老了,工作中没见过。
大章21:托管堆和垃圾回收
托管堆⭐
生命周期
访问一个资源所需的步骤:
- 调用IL指令newobj,为代表资源的类型分配内存(C#中用new操作符完成)。
- 初始化内存,设置资源的初始状态并使资源可用。类型的实例构造器负责设置初始状态。
- 访问类型的成员来使用资源(有必要可以重复)。
- 摧毁资源的状态以进行清理。
- 释放内存。垃圾回收器独自负责这一步。
C#为了简化编程,将大多数类的4这一步略去了,也就是不需要资源清理,由垃圾回收器来自动释放内存。遇到需要特殊清理不等待GC的类时,不推荐写unsafe代码,而是在类中调用额外的方法Dispose以按照自己的节奏清理资源。
1.从托管堆分配资源
NextObjPtr
CLR要求所有对象从托管堆分配源。进程初始化时,CLR划出一个连续的地址空间区域作为托管堆。CLR还会维护一个指针NextObjPtr,它指向下一个对象在堆中的分配位置。
一个区域被非垃圾对象填满后,CLR会分配更多的区域。这个过程一直重复直至整个进程地址空间都被填满。所以,你的应用程序的内存受进程的虚拟地址空间的限制,32位进程最多能分配1.5GB,64位进程最多能分配8TB。

new操作符执行流程
new操作符导致CLR执行以下步骤:
- 计算类型(包括基类继承的字段)的字段所需的字节数。
- 加上对象的overhead开销字段所需的字节数。每个对象都有2个开销字段:类型都西昂指针和同步块索引。对于32位应用程序,这2个字段各需32位,所以每个对象要+8字节;对于64位,各需要64位,所以每个对象要+16字节。
- CLR检查区域中是否有分配对象所需的字节数。如果托管堆空间足够,就在NextObjPtr指针指向的地址放入对象,为对象分配的字节会被清零。接着调用类型构造器(为this参数传递NextObjPtr)返回初始化好的对象的引用,并让NextObjPtr移动到新地址:原地址+这个类占用的内存字节数。
堆性能很强
正如上述所说,对于托管堆,分配对象只需要在指针上加一个值;寻找对象时,因为同时分配的对象内存是连续的(比如FileStream)且往往有业务联系,所以因为**局部化(locality)**会获得性能提升。
2.垃圾回收算法
垃圾回收的起因
托管堆性能并不是无敌的,前面说的有一个大前提——内存无限,CLR总能分配新对象。如果托管堆没有大小限制,那C#的执行速度要优于c了(托管堆的结构让它有比c运行时堆更快的对象分配速度)。但是内存不可能是无限的,所以CLR有“垃圾回收”GC。
垃圾回收的基本原理
回收分为两个阶段: 标记 –> 压缩
标记的过程,其实就是判断对象是否可达的过程。当所有的根都检查完毕后,堆中将包含可达(已标记)与不可达(未标记)对象。
标记完成后,进入压缩阶段。在这个阶段中,垃圾回收器线性的遍历堆,以寻找不可达对象的连续内存块。并把可达对象移动到这里以压缩堆。这个过程有点类似于磁盘空间的碎片整理。
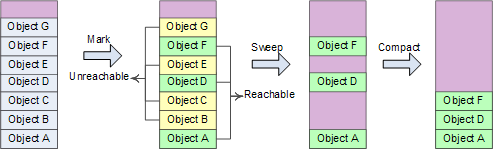
如上图所示,绿色框表示可达对象,黄色框为不可达对象。不可达对象清除后,移动可达对象实现内存压缩(变得更紧凑)。
压缩之后,“指向这些对象的指针”的变量和CPU寄存器现在都会失效,垃圾回收器必须重新访问所有根,并修改它们来指向对象的新内存位置。这会造成显著的性能损失。这个损失也是托管堆的主要缺点。
GC不是用引用计数
引用计数是COM(Component Object Model)使用的办法,GC并不是用这个,而是用的从根遍历。了解即可。说的是堆上的每个对象都维护着一个内存字段来统计程序中多少“部分”正在使用对象。随着每一“部分”到达代码某个不再需要对象的地方,就递减这个计数,直到0就可以删除了。
根(Root)
我们将所有引用类型的变量都成为根,类中定义的任何静态字段,方法的参数,局部变量(仅限引用类型变量)等都是根,另外cpu寄存器中的对象指针也是根。根是CLR在堆之外可以找到的各种入口点。
可达和不可达
对象可达与不可达(Objects reachable and unreachable):
如果一个根引用了堆中的一个对象,则该对象为“可达”,否则即是“不可达”。
引用跟踪 GC算法详解
CLR针对无法处理循环引用的情况,推出了引用跟踪算法,它只关心引用类型的变量,因为只有这种变量能引用堆上的对象。
GC时,
CLR先暂停进程中的所有线程,避免检查时对象状态被更改。
CLR进入GC的标记阶段。这个阶段中,CLR先遍历堆中所有对象,将同步块索引中的一位设为0:这一位是0代表着对象未被引用要删除,是1代表对象被引用着。
然后检查所有活动根,查看它们引用的对象,如果对象是null就跳过;否则就进行标记(就是上面说的一位改为1)。一个对象A第一次被标记后,CLR会检查这个对象A中的根(也就是这个对象A中自己的字段啥的),查看是否也引用了其他对象BCD,有就标记。当下次有根标记这个对象A的时候,就不再检查内部字段了。这样能解决循环引用:根引用了A,A中有B导致B被标记,B中有A发现A已经被标记就不标记了。
标记阶段结束,进入压缩阶段。这个阶段中CLR让堆中的所有幸存对象都紧挨在一起,使内存的地址空间得到释放。操作完内存后,将所有引用幸存对象的根减去所引用的对象在内存中偏移的字节数,从而保证每个根引用与以前一样的对象。
结束GC后,如果GC并没有分出足够的内存给新的new操作,就会抛出OutOfMemoryException异常。
根的作用域
根一旦离开作用域,它引用的对象就会变得“不可达”。
下面演示一个程序:
1 | void Man(){ |
代码运行会发现,程序只输出了一次,而不是每2秒一次。
原因是GC.Collect();这句,回收开始时,会假设堆中所有都对象不可达,而CLR发现Main方法再也没有继续用过变量t,所以会回收它的内存。
然而神奇的是,这么写也是不对的:
1 | void Man(){ |
正确的方法应该这么写:
1 | void Man(){ |
分代(Generation)算法
假设原则
CLR的GC对代码做出了以下几点假设:
- 对象越新,生存期越短。
- 对象越老,生存期越长。
- 回收堆的一部分,速度快于回收整个堆。
以此为方针,制定GC的机制。
回收机制
简单来说就是回收时,不可达的直接销毁,可达的压缩并放到下一代中,称作“存活对象”。
CLR托管堆支持3代:第0代,第1代,第2代。便于理解,可以将第0代的空间理解为256KB,第1代理解为2M,第2代理解为10M。新构造的对象会被分配到第0代。

如上图所示,当第0代的空间满时,垃圾回收器启动回收,不可达对象(上图C、E)会被回收,存活的对象被归为第1代。

当第0代空间已满,第1代也开始有很多不可达对象以至空间将满时,这时两代垃圾都将被处理:存活下来的对象(可达对象),第0代升为第1代,第1代升为第2代。
“预算”机制
如果说GC时,第1代中有一些“不可达”的存在,但是第1代已用的内存开销小于预算,那么就不用担心不够用,此时去扫描一遍第1代整体进行GC处理是非常多余的。所以这个时候,CLR就会选择忽略第1代的GC,直到某一次GC发现第1代的开销到达了预算。
实际CLR的代回收机制更加“智能”,如果新创建的对象生存周期很短,第0代垃圾也会立刻被垃圾回收器回收(不用等空间分配满)。另外,如果回收了第0代,发现还有很多对象“可达”,并没有释放多少内存,就会增大第0代的预算至512KB,回收效果就会转变为:垃圾回收的次数将减少,但每次都会回收大量的内存。如果还没有释放多少内存,垃圾回收器将执行完全回收(3代),如果还是不够,则会抛出“内存溢出”异常。
也就是说,垃圾回收器会根据回收内存的大小,动态的调整每一代的分配空间预算!达到自动优化。
GCNotification
该类在 第0代 or 第2代 回收时引发一个事件,可用来计算2次回收的间隔时间、分配了多少内存。
强制垃圾回收
垃圾回收触发方式
- 0代超过预算时自动触发GC
- 代码显式调用System.GC的静态Collect方法
- Windows报告低内存情况
- CLR正在卸载AppDomain、CLR正在关闭
System.GC
GC.Collect最复杂的重载签名也就这样:
1 | void Collect(Int32 generation, GCCollectionMode mode, Boolean blocking); |
- generation:最多回收到x代(最高2)。
- blocking:阻塞(非并发)或后台(并发)回收的一个Boolean值。
- mode:如下表。
| 符号名称 | 说明 GCCollectionMode枚举类 |
|---|---|
| Default | 等同于不传递任何符号名称。目前还等同于传递 Forced,但CLR未来的版本可能对此进行修改 |
| Forced | 强制回收指定的代(以及低于它的所有代) |
| Optimized | 只有在能释放大量内存或者能减少碎片化的前提下,才执行回收。如果垃圾回收没有什么效率,当前调用就没有任何效果 |
大对象
前面讨论的都是小对象,对于大对象(出书时是85000字节以上),CLR会区分对待:
内存不是在小对象的地址空间分配,而是进程地址空间的其他地方分配;总是第2代;目前不支持压缩。
垃圾回收模式
默认使用工作站GC模式,可以在配置文件中修改。
工作站
针对客户端的GC模式,假设其他应用程序不占用太多CPU资源。GC造成的延时很低,程序挂起时间很短。
服务器
针对服务端的GC模式,假设没有其他应用程序,所有的CPU都可用来辅助完成GC。优化了吞吐量和资源利用。每个CPU都跑一个特殊线程,它和其他线程并发回收自己的区域。
Finalize
Finalize方法对GC过程的影响
写代码时,理解的是GC时Finalize方法会被得到调用。实际上CLR是用了2个专门的列表来操作的。
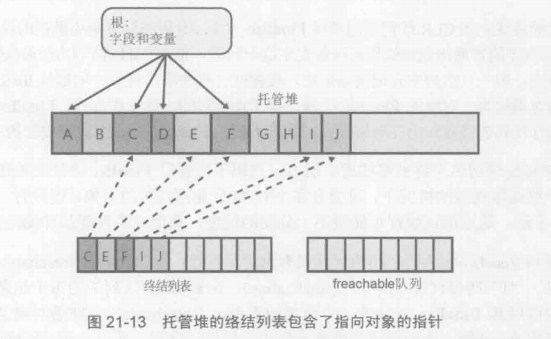
**一个是终结列表(finalization list)**,
对象创建(new)时,CLR检测到他们的Finalize方法被重写,就会把这些对象的指针扔进终结列表。
**另一个是F-reachable队列(finalization reachable Arrary)**,
一个无情的只顾执行对象Finalize方法然后将其移除的队列。
它们之间的协作:
终结列表中的对象在得知需要被回收后,会从终结列表转移到F-reachable队列中。此时,对象变得不在被认为是垃圾,还不能回收他的内存,被标记为垃圾但是不被认为是垃圾,叫复活了。垃圾回收器会递归该对象中所有的引用,让它们也不被内存回收,但是会被GC到更老的一代。下次GC时早已经执行完Finalize方法,会发现之前复活的对象们已经不可达,然后会回收。

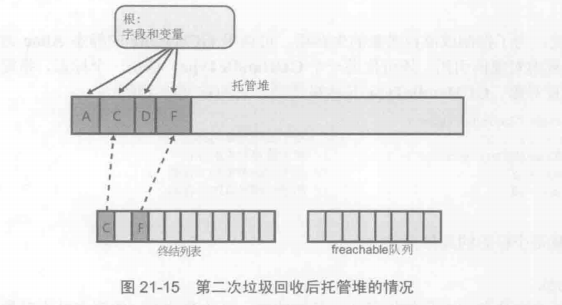
有一些特殊的类,需要清理本机资源
上面说的类都是只需要内存资源就行,但是有些类比如FileStream类型需要占用本机资源(打开文件保存句柄)。
GC清理不了这些本机资源。
这里就可以使用Finalize方法来清理本机资源。
Finalize
GC判定对象是垃圾后,会调用其Finalize方法。
1 | class SomeType{ |
CLR用一个特殊的高优先级的专用线程调用Finalize方法来避免死锁。Finalize方法如果阻塞(比如死循环),会导致该线程瘫痪,致使整个程序内存不停泄露并无法捕捉到此异常。
SafeHandle : CriticalFinalizerObject
1 | public abstract class Safehandle : CriticalFinalizerObject, IDisposable |
为了进一步深入了解SafeHandle类,上下都介绍一下:
父类,CriticalFinalizerObject
CLR特殊对待的类,它的行为:
- 首次构造时就进行此类Finalize方法JIT编译,保证不会出现内存满后无法编译Finalize导致无法执行的情况。
- 在所有非CriticalFinalizerObject派生类的Finalize执行完后才开始执行它们的Finalize,这样非CriticalFinalizerObject派生类可以在Finalize中安全调用它们。
- AppDomain被宿主应用程序强行中断,也会调用CriticalFinalizerObject类的Finalize方法。
子类1,SafeFileHandle
1 | public sealed class SafeFileHandle: SafeHandleZeroOrMinusOneIsInvalid |
GC句柄表
是说CLR为每个AppDomain都提供了一个**GC句柄表(GC Handle table),允许程序监视or手动控制对象的生存期。句柄表启动时是空白的,每个记录项都包含了对托管堆中的一个对象的引用,以及指出如何监视或控制对象的标志(flag)**。
使用System.Runtime.InteropServices.GCHandle类型在表中添加或删除记录项。在表中创建一个记录项调用该类的public static GCHandle Alloc(object value, GCHandleType type);,对象+标志。
GCHandleType有下面4种枚举类:
Weak
该标志允许监视对象的生存期。具体地说,可检测垃圾回收器在什么时候判定该对象
在应用程序代码中不可达。注意,此时对象的 Finalize方法可能执行,也可能没有执
行,对象可能还在内存中。
Weaktrackresurrection
该标志允许监视对象的生存期。具体地说,可检测垃圾回收器在什么时候判定该对象
在应用程序的代码中不可达。注意,此时对象的 Finalize方法(如果有的话)已经执行,
对象的内存已经回收。
Normal
该标志允许控制对象的生存期。具体地说,是告诉垃圾回收器:即使应用程序中没有
变量(根)引用该对象,该对象也必须留在内存中。垃圾回收发生时,该对象的内存可
以压缩(移动)。不向Ale方法传递任何 Gchandle Type标志,就默认使用
Gchandle T’ype Normal
Pinned
该标志允许控制对象的生存期。具体地说,是告诉垃圾回收器:即使应用程序中没有
变量(根)引用该对象,该对象也必须留在内存中。垃圾回收发生时,该对象的内存不
能压缩(移动)。需要将内存地址交给本机代码时,这个功能很好用。本机代码知道GC
不会移动对象,所以能放心地向托管堆的这个内存写入。
大章22:CLR寄宿和AppDomain
CLR寄宿
**寄宿(hosting)**使任何应用程序都能使用CLR的功能。
所有托管模块和程序集文件都必须使用 Windows PE文件格式,而且要么是 Windows EXE文件,要么是DLL文件。
开发CLR时, Microsoft实际是把它实现成包含在一个DLL中的COM服务器。很遗憾,这一句对于目前的我来说还无法深入理解,放着吧。
**垫片(slim)**,MSCorEE.dll。
CLRCreateInstance函数在MSCorEE.dll文件中实现。“垫片”的工作是决定创建哪个版本的CLR(1.0、2.0、3.0的CLR代码在MSCorWks.dll文件中;版本4则在Clr.dll文件中)。CLRCreateInstance函数可返回一个ICLRMetaHost接口。宿主应用程序可调用这个接口的GetRuntime函数,指定宿主要创建的CLR版本。然后,垫片将所需版本的CLR加载到宿主的进程中。
初识AppDomain
AppDomain是什么
CLR COM服务器初始化时会创建一个AppDomain。AppDomain是一组程序集的逻辑容器,它存在的目的是为了隔离。CLR初始化时创建的第一个AppDomain称为“默认AppDomain”,这个默认的AppDomain只有在Windows进程终止时才会被销毁。
在 Windows中,线程总是在一个进程的上下文中创建,而且线程的整个生存期都在该进程的生存期内。但线程和Appdomain没有一对一关系。一个Windows进程可包含多个Appdomain,所以线程能执行一个Appdomain中的代码,再执行另一个AppDomain中的代码。从CLR的角度看,线程一次只能执行一个Appdomain中的代码。
AppDomain长这样
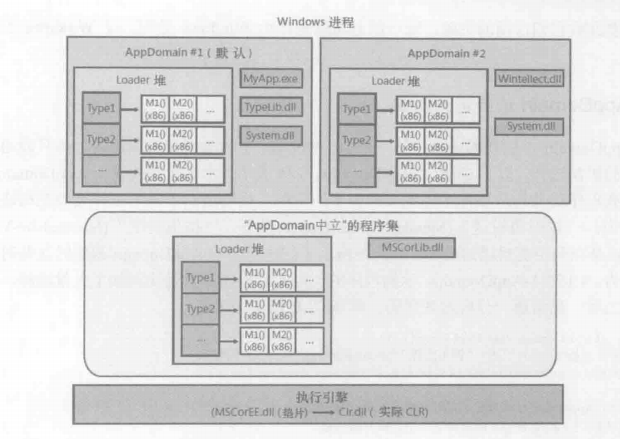
AppDomain #1和AppDomain #2完全不共享信息,以至于他们都用了System.dll却不共用。虽然有些浪费内存资源,但是这就是AppDomain的本质,“隔离”。
另外针对这种浪费,CLR也提供了一种AppDoamin中立加载方式的程序集。CLR会为它们维护一个特殊的Loader堆,该Loader堆中的所有资源都会共享给同一个进程中的其他AppDomain。省下资源的代价是这样的程序集永远不能卸载,只能终止Windows进程让Windows回收资源。
AppDomain特点
①一个AppDomain的代码不能直接访问另一个AppDomain的代码创建的对象。
一个AppDomain中的代码创建了一个对象后,该对象便被该AppDomain“拥有”。换言之,它的生存期不能超过创建它的代码所有的AppDomain。一个AppDomain中的代码要访问另一个AppDomain的对象,只能使用“按引用封送”或者“按值封送”的予以。这就强制建立了清晰的分割和边界,因为一个AppDomain中的代码不能直接引用另一个AppDomain中的代码创建的对象。这种隔离使AppDomain能很容易地从进程中卸载,不会影响其他AppDomain正在运行的代码
②AppDomain可以卸载
CLR不支持从AppDomain中卸载特定的程序集,但可以告诉CLR卸载一个AppDomain,从而卸载该AppDomain当前包含的所有程序集
③AppDomain可以单独保护
AppDomain创建后会应用一个权限集,它决定了想这个AppDomain中运行的程序集授予最大权限,正是由于存在这样的权限,所以当宿主加载一些代码后,可以保证这些代码不会破坏(或读取)宿主本身使用的一些重要数据结构
④AppDomain可以单独配置
AppDomain创建后会关联一组配置设置。这些设置主要影响CLR在AppDomain中加载程序集的方式,设计搜索路径、版本绑定重定向、卷影复制以及加载器优化
跨越AppDomain边界访问对象
一个AppDomain中的代码可以和另一个AppDomain中的类型和对象通信,但只能通过良好定义的机制执行。
抄个网上的可运行demo,做了解吧,以后深入ILRuntime之后再补一些理解:
1 | using System; |
操作AppDomain
卸载AppDomain
调用AppDomain的静态Unload方法可以实现卸载,CLR会按顺序执行以下操作:
- 挂起进程中的所有线程。
- 检查每一个线程栈,如果线程在执行即将卸载的AppDomain中的代码,就抛出一个ThreadAbortException,并执行所有遇到的finally块。线程终止,进程可继续运行。
- 所有线程离开目标AppDomain后,CLR遍历堆,为所有引用了目标AppDomain中的对象设置一个标志,告诉它们引用的真实对象已经不在了,再调用它们会抛出AppDomainUnloadedException异常。
- 强制垃圾回收目标AppDomain的对象。
- Unload执行完毕,恢复剩余所有线程运行,此刻调用了AppDomain.Unload方法的线程才会继续运行。
监视AppDomain
// TODO 本章后续的内容等实际工作用到再看吧。
大章23:程序集加载和反射
程序集
程序集可以用Load加载
使用System.Reflection.Assembly类的静态Load方法可以在运行时加载程序集。
1 | publiv class Assembly{ |
在Load内部,CLR会应用绑定重定向
在GAC(全局程序集缓存)中查找程序集。如果没找到就接着去应用程序的基目录、私有路径子目录和 codebase位置查找。如果调用Load时传递的是弱命名程序集,Load就不会向程序集应用版本绑定重定向策略,CLR也不会去GAC査找程序集。
找到指定程序集后,会返回对代表已加载程序集的一个Assembly对象的引用,否则会抛出IO异常。
使用反射
使用反射构建动态可扩展应用程序
通过反射的运行时序列化,使得应用程序在运行时可显式加载程序集构造类型的实例,再调用类型中定义的方法,这种绑定方法叫做晚期绑定。
反射的性能
- 反射造成编译时无法保证类型安全性,严重依赖字符串。搜索”int”是没法找到”System.Int32”的。
- 反射速度慢。
针对第2点,提一些具体情况来理解慢在哪里:
- 类型及其成员的名称在编译时未知,需要用字符串名称标识每个类型以及成员。反射机制会不停的对字符串进行搜索。
- 用反射调用方法时,必须将实参打包(pack)成数组;在内部,反射必须将这些实参解包(unpack)到线程栈上。导致CLR必须检查实参的数据类型是否正确、以及访问权限。
那么针对反射速度慢,有一些常见构造方案来实现类的动态行为,避免反射:
- 继承+重载。用父类变量接子类实例(转型),再调用基类虚方法。
- 接口。用接口变量接实例(转型),再调用接口定义的方法。
来点反射代码
程序集+反射
通过反射获取一个程序集定义了哪些类型。
1 | using System; |
类型对象
Type只是轻量级的对象引用,想要更多类型信息,可用TypeInfo对象。
1 | Type someType = typeof(int); |
批量加载

反射构造类型实例
类型
- System.Activator 的 CreateInstance 方法。
- System.Activator 的 CreateInstanceFrom 方法。
- System.AppDomain 的方法。4种实例方法,可以指定在哪个AppDomain中构造对象。
- System.Reflection.ConstructorInfo 的 Invoke 实例方法。绑定到特定的构造器到ConstructorInfo 中。
数组
System.Array 的 静态CreateInstance方法。
委托
MethodInfo 的 静态CreateDelegate方法。
开放类型
MakeGenericType方法。

反射+程序集加载 = 设计支持加载项的应用程序⭐
接口是中心。假设要写一个应用程序来无缝地加载和使用别人创建的类型,
- 创建“宿主SDK (Host SDK)”程序集,接口的方法作为宿主应用程序与加载项之间的通信机制使用。
- 创建单独的“宿主应用程序”程序集,引用“宿主SDK”程序集,随意开发。
来看一个上述的例子:
首先是宿主SDK
1 | // HostSDK.dll 程序集 |
其次是引用了HostSDK.dll的AddInTypes.dll程序集
1 | // AddInTypes.dll 程序集 |
然后我们写一个简单的Host.exe程序集的代码,也就是宿主应用程序。它必须引用HostSDK.dll程序集。
1 | // Host.exe 程序集 |
使用反射发现类型的成员
揭示WPF、ILDasm等的窗体设计器是如何利用反射实现需求的。
反射获取类型成员
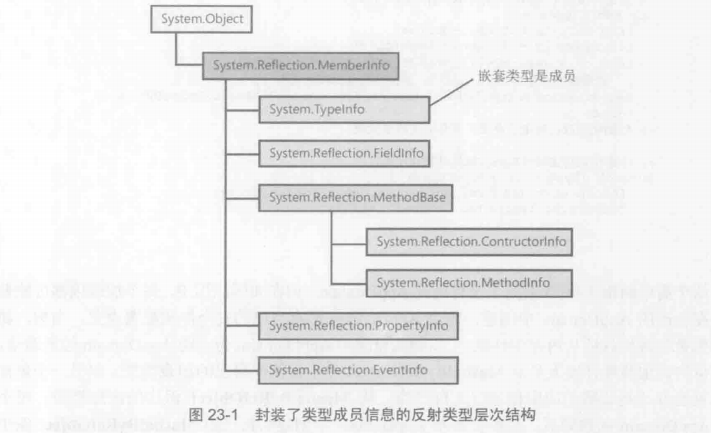
可以先用System.Reflection.MemberInfo抽象基类来接对象,然后再具体判别是什么:
1 | void Main(){ |
聊下MemberInfo
上面看到了MemberInfo类是成员层次结构的根,它的实现意味着所有派生成员的实现。下面解析下它:
MemberInfo属性和方法
- Name。成员名称
- DeclaringType。成员类型。
- Module。
- CustomAttributes。返回一个
IEnumerable<CustomAttributeData>,特性实例。
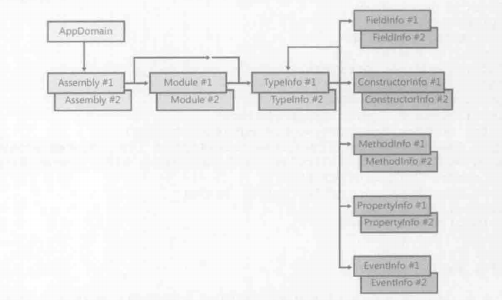
MemberInfo调用
FieldInfo
调用 Getvalue获取字段的值
调用 Setvalue设置字段的值
Constructorlnfo
调用 Invoke构造类型的实例并调用构造器
MethodInfo
调用 Invoke来调用类型的方法
PropertyInfo
调用 Getvalue来调用的属性的get访问器方法
调用 Setvalue来调用属性的set访问器方法
Eventlnfo
调用 Addeventhandler来调用事件的add访问器方法
调用 Removeeventhandler来调用事件的 remove访问器方法
使用绑定句柄减少进程的内存消耗
很多情况下会这么写代码:绑定了一组类型(Type)或类型成员(MemberInfo派生),并将这些对象保存在某种形式的集合中。然后只需要搜索这个集合就可以找到特定对象,并调用(比如Invoke)它。
这样写很方便,但是会导致一个问题,Type和MemberInfo派生对象需要大量内存,如果只是偶尔调用会造成严重浪费。
可以使用**运行时句柄(runtime handle)**代替对象以减小该Assembly的内存占用。使用System下的RuntimeTypeHandle、RuntimeFieldHandle、RuntimeMethodHandle。三个类型都是值类型,只包含了一个IntPtr,也就是一个句柄,指向AppDomain的Loader堆中的一个类型/方法/字段。可以使用Type.GetTypeFromHandle和Type.GetTypeHandle方法实现Type和IntPtr的相互转换。
大章24:运行时序列化
快速入门
序列化是将对象or对象图(比如数组)转换成字节流的过程,反序列化是将字节流转换回对象图的过程。
再举一些例子:
- ASP.NET利用序列化反序列化来保存和还原会话状态。
- WPF的对象剪切板由序列化反序列化实现。
- 深拷贝/备份 对象
- 不同端末之间的交互(pc与服务器)
序列化反序列化API
微软提供 BinaryFormatter 和 SoapFormatter 两个格式化器,他们都是实现了System.Runtime.Serialization.IFormatter这个序列化专用的接口。
SoapFormatter在.net3.5废了。
1 | var objectGraph = new List<String> { "Jeff", "Aidan", "Grant" }; |
序列化对象之后,会将类型的全名和字段都写入流中,甚至还会将程序集的信息写入进去。
我们尝试一下,发现直接转字符串是不行的,也是毕竟是流,要先转Byte,再转成人能看的懂的字节:
1 | var test = ""; |
最后输出这么个东西,
1 | test = "\0\u0001\0\0\0\u0001\0\0\0\0\0\0\0\u0004\u0001\0\0\0\u007fSystem.Collections.Generic.List`1[[System.String, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089]]\u0003\0\0\0\u0006_items\u0005_size\b_version\u0006\0\0\b\b\t\u0002\0\0\0\u0003\0\0\0\u0003\0\0\0\u0011\u0002\0\0\0\u0004\0\0\0\u0006\u0003\0\0\0\u0004Jeff\u0006\u0004\0\0\0\u0005Aidan\u0006\u0005\0\0\0\u0005Grant\n\v" |
转义符很多,程序集信息、字段信息确实都在里面。
反序列化
可以看到上面的那一串东西,
反序列化时,格式化器先获取程序集标识信息,并通过调用System.Reflection.Assembly的Load方法确保程序集已加载到正在执行的 Appdomain中。
然后在程序集中查找对应的类型,找不到就抛出异常。
找到类型就创建类型实例,并用流中的值对其字段初始化。如果字段名不完全匹配,就抛出SerializationException异常。
使类型可序列化
SerializebleAttribute
直接序列化一个类,会抛出SerializationException异常。因为你没有使用定制特性**[SerializebleAttribute]**。
该定制特性只能应用于引用类型(class)、值类型(struct)、枚举类型(enum)和委托类型(delegate)。其中,枚举类型和委托类型不必申明,他们总是可序列化的;对于类,可序列化特性不能被子类继承,但基类型如果不被申明可序列化那么子类无法可序列化,毕竟父类是子类的一部分。
控制序列化和反序列化
使用**[NonSerialized]**特性来使部分字段不参与序列化。
使用**[OnDeserialized]**特性来控制反序列化。它是用来修饰方法的,当实例所有字段被反序列化完后,方法才会被执行。你可以在里面给忽略的字段赋值或者标准化数据。
同样的还有特性**[OnDeserializing] (反序列化前)、[OnSerializing] (序列化前)、[OnSerialized] (序列化后)**。
1 | // 使用上面4个特性时,必须获取一个StreamingContext参数并返回void: |
格式化器序列化流程
微软提供了FormatterServices类型,里面只有静态方法,下面刨析一下流程。
序列化:
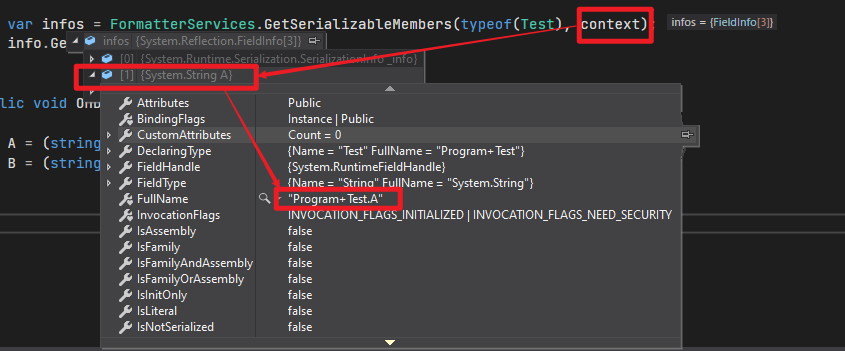
- 格式化器调用 Formatterservices的 GetSerializableMembers方法,反射获取类型的字段。
public static MemberInfo[] GetSerializableMembers(Type type, StreamingContext context) - 格式化器调用 Formatterservices的 GetObjectData方法,该方法输入一个MemberInfo[]输出一个Object[],而输出的Object[]是MemberInfo[]对应字段的值,两者一一对应。
public static Object[] GetObjectData(Object obj, MemberInfo[] members) - 格式化器将程序集标识和类型的完整名称写入流中。
- 格式化器然后遍历两个数组中的元素,将每个成员的名称和值写入流中。
反序列化:
- 格式化器从流中读取程序集标识和完整类型名称,如果程序集没加载到AppDomain中,就会加载它。确保程序集被加载后,格式化器将程序集标识信息和类型全名传给 FormatterServices的静态方法 GetTypeFromAssembly来获取反序列化对象的Type。
public static Type GetTypeFromAssembly(Assembly assem, String name) - 格式化器调用 FormatterServices的静态方法 GetUninitializedObject,为对象分配内存并初始化字段为null、0,但不调用构造器。
public static Object GetUninitializedObject(Type type) - 格式化器调用 Formatterservices的 GetSerializableMembers方法,构造并初始化一个MemberInfo[] 数组,等待着对应的字段值。
- 格式化器根据流中包含的数据创建并初始化一个 Object数组,是与3中一一对应的字段值。
- 将新分配对象、 MemberInfo[] 数组以及并行 Object数组(其中包含字段值)的引用传给
FormatterServices的静态方法 PopulateObjectMembers:
1 | public static Object PopulateObjectMembers(Object obj, MemberInfo[] members, Object[] data); |
这个方法遍历数组,将每个字段初始化成对应的值。
完全控制序列化/反序列化
可以自己定义序列化和序列化的方法,来实现完全控制,具体是用ISerializable和IDeserializationCallback来实现。
ISerializable 接口
只有GetObjectData一个方法,但是同时需要提供一个特殊签名的构造器,反序列化的时候会调用那个构造器,一般拿来暂存 SerializationInfo。
IDeserializationCallback接口
只有OnDeserialization一个方法。当然你可以不把赋值逻辑写在这里,可以直接写在构造器里,就不必实现本接口。
看个例子
1 | [] |
手动为父类实现 ISerializable
有时候父类没实现ISerializable,子类却想实现ISerializable来完全控制序列化,那么可以手动为父类实现 ISerializable。
观察下面代码,关键在于info.GetValue(baseType.FullName + "+" + fi.Name, fi.FieldType)和info.AddValue(baseType.FullName + "+" + mi[i].Name, ((FieldInfo) mi[i]).GetValue(this));。
1 | // ISerializable 接口要求的特殊构造器 |
简单看下 FormatterServices.GetSerializableMembers方法获取出来的东西:
为单例序列化的技巧
1 | // 单例序列化Helper |
流上下文 StreamingContext
前面的 ISerializable接口也好 FormatterServices.GetSerializableMembers方法也好,都用到了 StreamingContext这个类,它存储着关于程序集的上下文。
这个类内一共2个字段:
- Context:Object类型,一个对象引用,对象中包含用户希望的任何上下文信息。
- State:StreamingContextStates枚举类型,一组位标志( bit flag),指定要序列化/反序列化的对象的来源或目的地。

State就不多举例了,只说这个All:来源或目的地可能是上述任何一个上下文。这是默认设定。
序列化代理
自定义一个序列化器。看了一遍,感觉XLua的Loader是参照了这里的解决方案。
ISerializationSurrogate 接口
实现序列化代理项选择器,此选择器允许一个对象对另一个对象执行序列化和反序列化。
1 | public interface ISerializationSurrogate { |
实现之后怎么用?
1 | void Main(){ |
当格式化器准备好已登记的代理类型(如上述),调用格式化器的 Serialize方法时,会在SurrogateSelector维护的集合(一个哈希表)中查找每个对象的类型。如果发现一个匹配,就调用 ISerializationSurrogate.GetObjectData方法来获取写入流的信息。Deserialize方法同理。
上面提到的SurrogateSelector维护的集合是一个私有哈希表,调用AddSurrogate时,Type和StreamingContext构成了哈希表的key,对应的value就是ISerializationSurrogate对象。
代理选择器链
多个SurrogateSelector对象可链接到一起。
看一下 ISurrogateSelector怎么实现的,有点类似迭代器(不是真的实现了迭代器):
ChainSelector方法负责将参数插入到当前Selector后面。
GetNextSelector方法返回对链表中的下一个 IsurrogateSelector对象的引用(如果当前操作的对象是链尾,就返回null)。经过测试发现,GetNextSelector并不会像迭代器的 GetEnumerator方法一样调用一次就改变一次Current,单纯只是返回值罢了。
GetSurrogate方法返回对应Type的 ISurrogateSelector实例。
1 | public interface ISurrogateSelector { |
注意了,格式化器在里面找对应的Type,如果到了第一个就直接调用对应方法,不会再找第二个了。
例子
1 | class Program |
与之类似的SerializationBinder:反序列化对象时重写程序集/类型
讲的是 SerializationBinder类,格式化器.Binder可以指定,也就是也可以自定义。
1 | internal sealed class Ver1ToVer2SerializationBinder : SerializationBinder { |
大章25:与 WinRT组件互操作
WinRT is what?
**WinRT (Window Runtime, Windows运行时)**,是windows8带来的新类库。
WinRT 组件内部作为“组件对象模型”(COM)组件来实现。
WinRT 的特点是,他是异步的。
// TODO 本章只做基本了解,日后有需求补齐。
映射
WinRT与CLR是隐式映射的,通过各种解决方案来讲两者机制默默帮你处理成一致。
WinRT与.Net之间是显式映射的,写代码的时候调的是WinRT的API。

