
CLR Via C#个人笔记5 - 基本类型
大章14:字符、字符串和文本处理
字符Char类型
System.Char
- Char类型,在.NET中总是表示成16位Unicode代码值。
- Char类型,提供2个静态只读字段:
MinValue = \0和MaxValue = \uffff。 - Char类型,提供GetUnicodeCategory方法,它返回枚举类,表明该字符是Unicode标准定义的控制字符、货币符号、小写字母、大写字母、标点符号、数学符号还是其它字符。
- Char类型,在使用ToLower和ToUpper方法时,会需要使用到语言文化来转换,语言文化通过
System.Threading.Thread.CurrentCulture静态方法获取。
Char转换数值类型
- 强转,效率最高。
- 用Convert类的静态方法。
- 用IConvertible接口,效率最低,因为要装箱。
1 | Main(){ |
StringInfo处理字符
可以用StringInfo类提供的方法来实现处理字符、获取字符长度与文本元素等,具体不说了。
值得了解的是一个概念:Char实际代表一个16位Unicode码值,但是该值不一定就等于一个抽象Unicode字符。比如有的抽象Unicode字符是2个码值的组合,U+0625和U+0650字符组合起来构成一个抽象字符或者文本元素。
上述提到的一些Unicode抽象字符或者文本元素要求用2个16位值表示,第一个叫“高位代理项(high surrogate)”,第一个叫“低位代理项(low surrogate)”。两个代理项,Unicode可以表示100万以上不同的字符。
字符串String类型⭐
System.String
- String代表一个不可变(immutable)的顺序字符集。
- String直接继承自Object,所以是引用类型、总在堆上。
构造String
string虽然是引用类型,却不可以用new、只能用简化过的语法:
1 | String s = "Hi there."; |
可见,String构造新实例用的是ldstr(load string)指令 而不是类通用的newobj指令,来处理从元数据获得的字面值(literal) “Hi there.”字符串。
逐字字符串@
推出这个是因为C#编译器会对String的实例实行转义机制,在使用比如输出时,会把诸如\r \n进行语义转换。
逐字字符串(verbatim string),用@关键字。抛弃转义,所有字符都被视为字符串的一部分。
字符串是不可变的⭐
字符串是不可变(immutable)的,也就是说一经创建就不能更改任何字符。
- 对字符串的变更操作(比如
Substring())会返回新的字符串。因为它们都在堆上,所以频繁对字符串进行处理会影响GC。执行大量字符串操作更推荐用StringBuilder类。 - 不可变所以不会发生线程同步问题。
- CLR会将”字符串留用“,多个String实例共享一个String内容。
字符串留用⭐
字符串一经创建不可变更,所以CLR为了提升性能推出了字符串留用(string interning)机制。
CLR在初始时会创建一个空的内部哈希表,key是字符串,value是对托管堆中String对象的引用。String类提供了2个方法来访问这个内部哈希表:
1 | // 把入参str作为哈希值去找内部哈希表,如果存在则返回引用,如果不存在则创建入哈希表并返回引用 |
注意了,这种字符串留用机制录入的字符串,因为哈希表引用着String,所以永远不会被GC;一般的新建字符串方法,会被GC。
重点来了,那么,对于我们日常的字符串写法var s = "Hello";会进入留用哈希表吗?答案是不一定,但大概率会。
书中说了,如果元数据中存在“字面值”字符串定义,C#编译器会在加载AppDomain时对这些字面值进行留用。
在CLR4.5以前的版本中,由于System.Runtime.CompilerServices.CompilationRelaxationsArrtibute和System.Runtime.CompilerServices.NoStringInterning两个标志的标记,CLR会不留用。
目前的CLR版本中,我测试了,默认是留用的。但是注意了,留用只限于元数据中存在的、编译时就可确定的那些字面值。运行时确定的是不行的。下面展示:
1 | // 测试 |
最后,怎么说呢,这块概念很重要,便于去理解C#留用机制的实现。但是真写代码是不会用这么麻烦的String.Intern写法的。
字符串池
字符串留用机制之外的另一个优化。
CLR处理字面值字符串并嵌入元数据,同一个字符串在源代码中多次出现,把它们都嵌入元数据会使生成的文件无谓地增大。
所以只在元数据中嵌入一次该字符串,剩下的全部是持有那个字符串的实例。
比较字符串(语言文化)
了解即可。
用来比较的String.Equals();String.Compare()等的重载,一般都有一个StringComparison枚举类型或者CompareOptions枚举类型参数,这2个枚举类型跟语言文化有关,可以改变比较的思路。下面进行展示:
1 | // StringComparison枚举类型 |
如果进行一些url、值得比较,不需要语言文化,那就选择忽略语言文化。
下面讲一下语言文化,.NET把语言文化放在System.Globalization.CultureInfo类表示一个”语言/国家“对,例如”en-US“。
在CLR中,每个线程都关联了2个特殊属性,每个属性都引用一个CultureInfo对象。它们是:
- CurrentUICulture属性:在GUI或者Web窗体等等程序中,UI元素的显示资源用的就是它。
- CurrentCulture属性:不适合CurrentUICulture属性的场合就用它,例如数字和日期格式化、字符串比较。
在许多计算机上,线程的CurrentUICulture属性 与 CurrentCulture属性都被设为同一个CultureInfo对象。但是也可以不同。
下面根据语言文化进行比较的示例:
1 | void Main(){ |
高效率构造字符串StringBuilder类型
StringBuilder是什么
StringBuilder代表可变(mutable)字符串。也就是说StringBuilder的大多数成员都能更改字符数组的内容,同时不会造成在托管堆上分配新对象。
只有以下2种情况会分配新对象:
- 动态构造字符串,其长度超过了设置的“容量”。
- 调用StringBuilder的ToString方法。
StringBuilder是怎么做的
StringBuilder对象包含一个字段,这个字段引用了由Char结构构成的数组。可以利用StringBuilder的各个成员来操纵该字符数组,高效缩短字符串或更改字符串中的字符,而不是和String一样只能新建。
如果字符串变大,超过了事先分配的字符数组大小,StringBuilder会自动分配一个新的、更大的数组,复制字符并开始使用新数组。前一个数组被GC。
使用ToString转换为String对象。
StringBuilder构造概念
StringBuilder就是个普通的类,不会把他当作基元类型。
下面介绍一些StringBuilder的核心元素:
1.最大容量:一个Int32值,指定了能放到字符串中的最大字符数。默认值是Int.MaxValue(约20亿)。
创建完之后,这个最大容量就不能修改了。
2.容量:一个Int32值,指定了由StringBuilder维护的字符数组的长度。默认为16,可以在构造时自己设置。
向字符数组追加字符时,StringBuilder会检测数组会不会超过设定的容量。如果会,StringBuilder会自动倍增容量字段,用新容量来分配新数组,并将原始数组的字符复制到新数组中。随后,原始数组可以被GC。尽量避免分配不合适导致的动态扩容,会影响性能。
3.字符数组:一个由Char结构构成的数组,负责维护“字符串”的字符内容。字符数可用StringBuilder的Length属性来获取,它总是 <= “容量”、“最大容量”。
4.构造器:可以在构造StringBuilder时传递一个String来初始化字符数组。不传递字符串,数组刚开始就不会包含任何字符,Length=0。
StringBuilder构造实际
上面介绍了核心概念,下面讲一下StringBuilder核心、常用的成员:
| 成员名称 | 成员类型 | 说明 |
|---|---|---|
| MaxCapacity | 只读属性 | 返回字符数组能容纳的最大字符数(最大容量)。 |
| Capacity | 可读可写属性 | 字符数组的长度(容量)。比MaxCapacity大会抛错。 |
| EnsureCapacity(Int32) | 方法 | 如果传给方法的值大于当前容量,当前容量就会自动增大;如果小于当前容量,就不做。 |
| Length | 可读可写属性 | 存储着的字符数组的实际长度(使用)。设置为0就会重置StringBuilder为空字符串。 |
| Chars[] | 可读可写索引器属性 | 用于操作指定索引位置的字符。 |
| ToString | 方法 | 返回代表StringBuilder的字符数组的一个String。 |
| Equals | 方法 | 只有2个StringBuilder对象具有相同的 最大容量、字符数组容量和字符内容才返回true。 |
| CopyTo | 方法 | 将StringBuilder的字符内容的一个子集复制到一个Char数组中。 |
| Append、Insert等插入方法 | 方法 | 向字符数组中插入一个对象。如由必要,数组会进行扩容。 |
个人觉得,主要就是看MaxCapacity、Capacity、Length这三个容量相关的核心属性,以及EnsureCapacity(Int32)方法的机制。
ToString方法
默认实现
面对对象理念下,所有类型都有责任提供转换为字符串表示的方法。
System.Object提供了一个public、virtual的ToString默认实现,它只返回对象所属类型的全名。
C#的许多核心类型(Byte、int、uint、double等)都进行了ToString方法重写。
IFormattable接口
用于指定 格式(比如x进制、日期) 和 语言文化:
1 | public interface IFormattable { |
所有基元类型、所有枚举类型都定义或自动实现了IFormattable接口。
介绍下这个签名的2个参数,
- format,告诉方法如何格式化对象。比如DateTime类型支持用“d”表示短日期、“Y”表示年等。
- formatProvider,提供具体文化信息。可以传null,默认调用线程关联的语言文化信息。System.IFormatProvider实现的类型不多,CultureInfo算一个。
String.Format方法
就是常用的format方法,在内部Format方法会调用每个对象的ToString方法来获取对象的字符串表示,再依次拼接。
StringBuilder.AppendFormat方法也差不多。
当然,每个对象都要调用ToString意味着他们都要使用他们的常规格式和调用线程的语言文化来格式化,但是你可以像下面这样指定:
1 | String s = String.Format("On {0:D},{1} is {2:E} years old.", |
定制格式化器
可以通过实现ICustomFormatter接口和IFormatProvider接口实现自定义StringBuilder的AppendFormat方法的行为。它将不再为每个对象调用ToString,而是调用定制的方法。
具体看书,提供一下调用。
1 | void Main { |
解析字符串获取对象:Parse
能解析字符串的任何类型都提供了公共静态方法Parse。它们如下形式:
1 | // String解析为Int32 |
编码解码:字符和字节的互转
不同的字节码
只说CLR常见的2个:
- UTF-16:每个16位字符编码成2个字节,又称作“Unicode编码”。
- UTF-8:将部分字符编码成1 or 2 or 3 or 4个字节。值在0x0080下用1个字节,适合美国语言;值在0x0080~0x07FF用2个字节,适合中东语言;值在0x07FF以用3个字节,适合东亚语言;代理项对(surrogate pair)表示4个字节。
其他的诸如UTF-7、UTF-32、ASCII之类的就不展开了。
编码解码
用System.IO.BinaryWriter 或者 System.IO.StreamWriter类型将字符串发送给文件或网络流时,通常要进行编码;
用System.IO.BinaryReader 或者 System.IO.StreamReader类型从文件或网络流读取字符串时,通常要进行解码。
不显式指定一种编码方案,所有这些类型都默认使用UTF-8。
Sytem.Text.Encoding
要编码或解码一组字符时,应获取从Sytem.Text.Encoding派生的一个类的实例。
1 | void Main(){ |
字节流
字节流通常以数据块(data chunk)的形式传输。
不能以常规方法解码,假设要通过System.Net.Sockets.NetworkStream来读取UTF-16字符串,可能从流中先读取5个字节,再读取7个字节。如果使用UTF-16的Encoding来解码,那么第一次GetString就只能正确解码2个字,第二次GetString就只能正确解码3个字,那样数据就损坏了。
字节块正确的解码方法是:
- 获取一个Encoding派生对象,再调用其GetDecoder方法
- 方法返回对一个新构造对象的引用,该对象的类型从System.Text.Decoder类派生。
- 执行Decoder对象的GetChars或者GetCharCount方法:它会尽可能多地解码字节数组,假如字节数组包含的字节不足以完成一个字符,剩余的字节会保存到Decoder对象内部。下次再调用其中一个方法时,Decoder对象会利用之前剩余的字节再加上传给它地新字节数组进行解码。
上面提到的,
GetChars:将一个字节序列解码为一组字符。
GetCharCount:计算对一个字节序列进行解码所产生的字符数,不实际进行解码。
安全字符串SecureString
System.Security.SecureString
就是说String对象可能在GC之前,被非托管代码操作或者执行unsafe方法,导致String对象的使用内存无法被重用,导致String一直在进程内存里逗留着。万一这个String式机密数据,那就会泄露。
为了解决上述问题,推出了System.String,System.Security.SecureString类型。
SecureString类型的字符串是加密的。会为它分配一块非托管内存块,为了逃避GC。
它也有AppendChar、InsertAt、RemoveAt这几个方法,便于增删改查,但是它们都是通过解密后处理再加密实现的。
访问它的话,需要用unsafe方法,因为要访问到非托管内存。
大章15:枚举类型和位标志
枚举类型
枚举类型(enumerated type)是值类型
枚举类型都从System.Enum派生,System.Enum从System.ValueType派生,所以枚举类型是值类型,会有装箱拆箱发生,但是不能定义定义任何方法、属性或事件。
另外,枚举类型也是基元类型。
枚举类型内部构造
比如我们这么定义一个枚举类型:
1 | public enum Color { |
C#编译器会这么看待它(不是真的生成这样的代码,不过效果相同):
1 | public struct Color : System.Enum { |
枚举类型的值
C#枚举类型的值默认是int类型的。它还可以是byte、sbyte、short、ushort、int、uint、long、ulong。
1 | // 值定义成byte类型 |
枚举类型常用方法
简单说下枚举类型名称<=>值之间得转换。
1 | void Main(){ |
位标志
什么是位标志(bit flag)
比如要解决这么一个问题:
假如我从早上到晚上一天有12节课,我希望用一串数来记录每节课我有没有去。
首先会想到定制规则,1是去0是不去:

会变成如上一串数字,解决了问题,但这不就是一个二进制数吗?转换成十进制数902。
这串数字就是一种位标志。
下面也会提到“0x0001”这样的位标志,“0x”指的是16进制,“0001”是16进制数。
什么是位运算
现在,我有新的需求:我发现1、2节课漏记了去上课了,需要补上。
那只需要用 001110000110 | 110000000000 得运算结果就完成了,转换成十进制它看上去就是 “902 | 3072”,计算得出的结果更新就行了。
1 | void Main(){ |
或者,我想检查1、2节课我去上课了没,那也很容易:
用 001110000110 & 110000000000 ,也就是 “902 & 3072” 判断计算得到十进制结果的是不是0,如果是0那就意味着并不重复,可以去。
1 | void Main(){ |
C#位运算
假设如果 A = 60,且 B = 13,现在以二进制格式表示,它们如下所示:
A = 0011 1100
B = 0000 1101
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 如果同时存在于两个操作数中,二进制 AND 运算符复制一位到结果中。 | (A & B) 将得到 12,即为 0000 1100 |
| | | 如果存在于任一操作数中,二进制 OR 运算符复制一位到结果中。 | (A | B) 将得到 61,即为 0011 1101 |
| ^ | 如果存在于其中一个操作数中但不同时存在于两个操作数中,二进制异或运算符复制一位到结果中。 | (A ^ B) 将得到 49,即为 0011 0001 |
| ~ | 按位取反运算符是一元运算符,具有”翻转”位效果,即0变成1,1变成0,包括符号位。 | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。左操作数的值向左移动右操作数指定的位数。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。左操作数的值向右移动右操作数指定的位数。 | A >> 2 将得到 15,即为 0000 1111 |
C#位标记:[Flags]特性
C#的位标记离不开[Flags]特性,
这个特性的作用就是someEnum.ToString()是”ReadOnly, Hidden”这个枚举名称的字符串。
如果没有[Flags]特性,就会为具体的数值。
1 | [] //增加Flags标记便可申明一个位标记 |
数值转换为标志字符串
存在[Flags]特性时枚举实例.ToString()的工作流程:
- 获取枚举类型定义的数值集,并按降序排列。
- 每个数值将会与枚举实例的值进行“按位与&”计算,假如结果等于该数值,与该数值关联的字符串便会追加到输入字符串中,对应的位会被认为考虑过了(设置为0)。反复到每一个数值都计算完。
- 如果2中计算出的数值结果仍然不为0,说明枚举实例的一些“1”状态的位,在枚举类里压根没定义过,那么ToString直接返回枚举实例原始值的字符串。
- 如果2中计算出的数值结果为0,那么再检查枚举实例原始值:
- 如果枚举实例原始值不为0,那么ToString返回符号名称之间以逗号分隔的字符串。
- 如果枚举实例原始值为0,那么再检查枚举类型定义的符号中有没有值为0的,有的话ToString返回值为0的符号名称;没有的话ToString返回值“0”。
为什么能这么做?因为确保过枚举类型中定义的每一个枚举的值,都只代表一位的开关。就是0001、0010、0100这样下去,转换成十进制的话,全是2的整数次方。
但是也有唯一一个例外不是2的整数次方,比如可以添加一个枚举类Action.All = Action.Walk | Action.Run | Action.Speak,它的值是0x0007。
1 | [] |
标志字符串转换为数值
将逗号分割的符号字符串转换为数值,这是通过Enum的静态方法Parse和TryParse来实现的。
1 | Action a = (Action) Enum.Parse(typeof(Action),"3"); |
Enum的静态方法Parse和TryParse的工作流程:
- 删除字符串头尾所有的空白字符。
- 如果字符串第一个字符是数字、+、-,该字符串会被认为是一个数字,方法返回会一个枚举类型实例,数值为字符串转换后的数值。
- 将2得到的数值转换为2进制,再将每一位的”1”都单独分割成一个2进制数,用
,分隔,比如0110 => 0100,0010。 - 把3中得到的每一个数都去枚举类型中匹配,如果有匹配不到的就抛错ArgumentExpection;如果匹配的到就与动态结果进行“按位或|”计算(动态结果初始值是0),再查找下一个符号。
- 查找并找到所有标识后,以Object形式返回这个动态结果值所表示的枚举类型名称们,格式是“名称1 , 名称2”。
上面的3-4我是猜的,因为书里写的token我不明白,搜也没搜到。
但是像这么做的确可以实现,4的目的,是记录已经找到的枚举类型名称罢了。
向枚举类型添加方法
枚举类型中不能定义方法,但是可以通过拓展方法来实现模拟向枚举类型添加方法。
大章16:数组
数组是什么
数组 is a Array
所有数组类型都隐式从System.Array抽象类派生,System.Array又从Object派生,所以数组都是引用类型。
所有数组同时隐式实现IEnumerable、ICollection、IList接口。
多维数组 ≠ 交错数组
1 | void Main(){ |
创建一个数组
new一个数组⭐
1 | Int32[] myIntegers = new Int32[100];// 包含100个Int32的数组 |
像上面这样new,
- 首先,数组是引用类型,所以数组都是在堆里的,分配内存也是在堆里分配。
- 其次,数组单个元素的类型,
如果是值类型比如上面的Int32,就会在托管堆上分配100个未装箱Int32所需的内存块,并给每个Int32实例都附上default值0;
如果是引用类型比如上面的Control,就会在托管堆上分配50个Control引用的内存块,并给每个引用都附上null。 - 最后,给一个类型对象指针、一个同步块索引和一些overhead字段(开销字段)分配内存。
- 返回上面分配完的内存块地址,保存到array变量中。
堆上的图大概可以这么理解(这里给myControls数组提前new了几个实例):

初始化数组元素 语法糖
C#提供了语法糖方便初始化数组,由编译器帮你推断最佳类型:
1 | // 创建+初始化数组 |
数组转型
两种方法:
1.显式或隐式转型:要求数组维数相同、且必须存在从元素源类型到目标类型的显式或隐式转换。所有的值类型都不允许用这个方式转。
1 | FileStream[,] fsArr = new FileStream[5,10]; |
2.Array.Copy(fromArr, toArr, length):浅拷贝,可以拆箱装箱所以能接受值类型。
1 | int[] intArr = new int[5]; |
所有数组都会偷偷…
所有数组都隐式派生自System.Array
随意声明一个数组,它都隐式派生自System.Array类型,
System.Array类型定义了很多常用的实例方法、静态方法和属性,比如Clone、CopyTo、GetLength、IndexOf等。
所有数组都隐式实现IEnumerable、ICollection、IList接口
System.Array类型也实现了IEnumerable、ICollection、IList这几个接口,但是它是把他们都当作Object类型来处理的。
全当作Object类来处理会很不方便,影响性能,甚至可能患有类型不安全,所以数组重新实现了这几个接口,用泛型:
当你新创建 一维数组 时,会将其类型传入并实现IEnumerable<T>、ICollection<T>、IList<T>这几个泛型接口。同时为会传入类型的父类也实现这3个接口,直到Array的默认实现。可以看结构展示:
1 | void Main(){ |
另外,如果是值类型数组,就只会为值类型数组本身实现这3个泛型接口,其父类不会再自动实现了,和引用类型数组是不一样的。
数组的传递和返回
要理清楚,数组是引用类型,数组的元素类型可能是堆上分配的值/引用类型。
所以,数组作为参数,传的一定是地址。
但是数组元素作为参数,传的可能是地址可能是逐位复制的值。
1 | void Main(){ |
创建下限非0的数组
用静态方法 Array.CreatInstance(Type type, int[] lengths, int[] lowerBounds) 来实现。
该方法为数组分配内存,将参数信息保存到数组的内存块开销(overhead)部分。
1 | // 以下实现了创建二维数组:Decimal[2005...2009][1...4] |
数组循环的内部检查
数组循环
用例子解释,执行以下代码:
1 | void Main(){ |
a.Length检查:只做一次
对于上述循环操作,只会执行一次a.Length属性获取到数组的实际长度,再将其放到一个临时变量中,后续的循环迭代检查都是用这个临时变量了。
index检查:为什么0基一维更快?
对于索引值index,JIT也会进行检查。
JIT编译器知道for循环要访问0到Length-1的数组元素,所以它会生成代码在运行时测试所有数组元素的访问都在数组有效范围内:检查是否 (0 >= Get.LowerBound(0)) && ((Length-1) >= a.GetUpperBound(0)),这个检查在循环之前发生。如果在数组有效范围内,JIT不会再循环内部生成代码验证每一次数组访问是否有效。
但是对于非0基一维数组(多维数组和非0基一维数组)的循环迭代,JIT就没法这么信任,它必须在循环内部进行越界检查,并且它还需要从指定索引中减去数组下限,所以很影响性能。
对于这种情况,推荐用0基一维数组构成的多维数组,也就是交错数组int[][]代替矩形数组。
unsafe访问数组:关闭检查
使用unsafe关键字,可以关闭索引上下限检查,但是要慎用:它直接访问内存,越界不会抛出异常,但是会损坏内存中的数据,破坏类型安全性制造安全漏洞。
写法如下:
1 | private const int my_length = 10000; |
不安全的数组访问和固定大小的数组
unsafe数组
unsafe数组访问非常强大,它允许访问:
- 托管堆上的数组中的元素(上面的就是)。
- 非托管堆上的数组中的元素(比如用Marshal.SecureStringToCoTaskMemUnicode方法返回一个数组,并用不安全的数组访问)。
- 线程栈上的数组中的元素,利用stackalloc,下面介绍。
线程栈上的数组
通常结构体内写数组也只是持有数组的引用,但是可以如下将数组嵌入结构实现在栈上分配数组的内存。
在结构体中嵌入数组需要满足以下条件:
- 类型必须是结构(值类型),不能在类(引用类型)中嵌入固定大小缓冲区字段(栈上数组)。
- 字段或其定义结构必须用unsafe关键字标记。
- 数组字段必须用fixed关键字标记。
- 数组必须是一维0基数组。
- 数组的元素类型必须是:Boolen,Char,SByte,Byte,Int16,Int32,Int64,UInt16,UInt32,UInt64,Single,Double。
1 | void Main(){ |
大章17:委托
初识委托
委托是什么?
得先提到回调函数,回调函数是一个非常重要的机制,在C/C++中通过qsort函数获取指向一个回调函数的指针,而在.NET中,使用委托来实现回调函数。
委托比C/C++的回调函数强在它能确保类型安全、且提供更多更强大的功能。
如何使用委托
1 | // 0.声明委托,它的实例引用一个方法。该方法签名:获取一个int参数,返回void |
委托类型揭秘
委托就是类
声明一个委托,
1 | internal delegate void Feedback(int val); |
这一行代码,C#编译器会这么定义一个类:
1 | internal class Feedback : System.MulticastDelegate { |
- 可见委托其实就是个类,所以委托能定义到类中,也能定义到类外。只要能定义类的地方就能定义委托,可见性随声明委托时用的可见性一样。
- 所有的委托都继承自System.MulticastDelegate。
委托构造器
上面已经知道委托都继承自System.MulticastDelegate类,那么要构造一个委托肯定离不开这个类,先展示一下这个类内的重要成员:
| 字段 | 类型 | 说明 |
|---|---|---|
| _target | System.Object | 这个字段引用的是回调方法要操作的对象。当委托对象包装静态方法时,这个字段返回null;当委托对象包装实例方法时,这个字段引用回调方法要操作的对象。 |
| _methodPtr | System.IntPtr | 一个内部的整数值,CLR用它标识要回调的方法 |
| _invocationList | System.Object | 通常为null。构造委托链时它引用一个委托数组(详见下节) |
再聊构造器,所有委托都有一个构造器,它获取2个参数:一个是对象引用,另一个是引用了回调方法的整数。
C#编译器知道要构造的是委托,在传入诸如
new FeedBack(Method_B)这样的参数时,会分析源代码来确定引用的是哪个对象和方法。对象引用被传给构造器的object参数,标识了方法的一个特殊IntPtr值被传给构造器的method参数。对于静态方法,会给object参数传递null值。构造器方法体内部将这两个实参分别存在_target、_methodPtr这两个私有字段里。
最后将_invocationList字段设置为null,这个字段后面讨论。
所以,每个委托对象实际都是一个**包装器(wapper)**,其中包装了一个方法和调用该方法时要操作的对象。结构图:

委托使用揭秘
委托调用
C#编译器会自动将委托的调用转换为Invoke:
1 | FeedBack fb = null; |
可以查看IL代码:
1 | IL_0009:callvirt instance void Feedback::Invoke(int32) |
委托链
委托链,也就是用委托回调多个方法。
下面制造一个委托链并调用,堆流程刨析:
1.初始化委托链(委托)
1 | internal delegate void FeedBack(int val); |
2.将委托添加到链中
1 | fbChain = (Feedback) Delegate.Combine(fbChain, fb1); |
此时Combine方法内部,发现fbChain是null,所以直接返回fb1中的值。
3.再将委托添加到链中
1 | fbChain = (Feedback) Delegate.Combine(fbChain, fb2); |
此时Combine方法内部,发现fbChain内部已经包含了一个委托(fb1),所以会构造一个新的委托对象。初始化这个新委托对象时,**_invocationList字段**被初始化为引用一个委托对象数组。
数组的第一个元素(索引0)被初始化为重包装了fbChain内部方法的委托,数组的第二个元素(索引1)被初始化为重包装了fb2内部方法的委。
最后,fbChain被设为引用新建的委托对象。
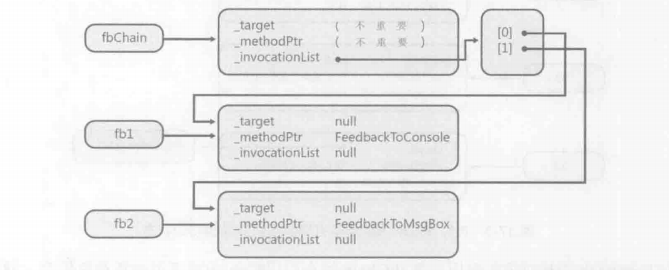
后续如果继续向委托链+=新委托,每次都会新建一个委托数组放入**_invocationList字段中,让原先的数组进入GC,我称之为委托链的不可变性**。至于为什么要新建而不是扩容,我估计是因为数组长度不可变,比起扩容,new比较省事安全吧。
4.对委托链进行调用
1 | fbChain(2); |
首先知道,fbChain会被转换为 fbChain.Invoke。
Invoke时发现内部字段_invocationList不为null,就能判断为一个委托链,对其进行循环遍历数组并依次调用各个委托中的方法。
5.对委托链进行Remove
倒序循环遍历_invocationList数组,匹配_target和_methodPtr字段相同的元素进行删除,只删除一个元素。
显式调用委托链
起因是委托链遍历调用,返回值只能有一个,且某一元素出错会导致后续的委托都出错,就很不健壮。
所以MulticastDelegate类提供了实例方法GetInvocationList,用于显式调用链中的每一个委托:
1 | public abstarct clas MulticastDelegate : Delegate { |
用这个方法,就可以自己显式调用每一个委托,加上诸如 try catch 的定制化处理。
C#泛型委托
尽量少定义委托
主要是就定义的太多了,比如微软定义的:
1 | public delegate void TryCode(Object userData); |
压根就是重复的签名,根本没必要定义的这么杂乱,所以推荐用泛型委托。
Action和Func
微软定义好的泛型委托就是Action和Func,Action有16个Func有17个。
1 | public delegate void Action();// 这个不是泛型,所以不算 |
C#委托语法糖
不必新建委托对象
1 | // 定义签名以及调用方法 |
省去new,当然IL代码还是会一样生成的。
不必定义方法(lambda)
1 | SomeMethod(num => { |
其实就是匿名函数,IL代码也一样会生成一个同签名的方法,不过方法名不确定(编译时才知道)且为private。
直接使用局部变量(lambda)
1 | public void OtherMethod(){ |
其实在IL的生成代码里看,这个匿名方法之所以能直接用局部变量、实例变量,是因为它定义为一个方法内的嵌套类。
1 | public void OtherMethod(){ |
+=和-=操作符
被重载了,分别是Delegate.Combine、Delegate.Remove。IL代码完全一致。
委托和反射
- 获取委托,使用
MethodInfo.CreateDelegate(委托Type, 实例对象Object)方法。 - 调用委托,使用
Delegate.DynamicInvoke方法。
1 | class Program |
大章18:定制特性
定制特性(custom attribute)
什么是特性
比如public、private、static这些就算是特性。
但是如果能定义自己的特性,比如定义一个类型,指出该类型能够通过序列化来进行远程处理。
什么是定制特性
定制特性其实是一个类型的实例。它必须从类System.Attribute派生。
如何使用特性
1.使用特性的语法和构造方法非常相似,是因为其实就是对Attribute类进行实例化。但也有点不同,构造器用到的参数叫**定位参数(positional parameter),用于设置字段或属性的参数成为命名参数(named parameter)**。
比如:
1 | [] |
这一句里,”Kernel32”是构造器需要的参数,也就是定位参数,它是必要的;“CharSet”和“SetLastError”是设置内部属性的,也就是命名参数,是非必要的。
2.此外,特性写法也很多种,Attribute后缀可以写可以不写,以下4条是等效的:
1 | [][Flags] |
定制特性例子
.NET类库定义了几百个定制特性,可将他们应用于自己源代码中:
- DllImport特性应用于方法,告诉CLR该方法的实现位于指定dll的非托管代码中。
- Serializable特性应用于类型,告诉序列化格式化器一个实例的字段可以序列化和反序列化。
- AssemblyVersion特性应用于程序集,设置程序集的版本号。
- Flags特性应用于枚举类型,枚举类型就成了位标志(bit flag)集合。
特性应用范围
CLR允许将特性应用于可在文件的元数据中表示的几乎任何东西。比如:
- TypeDef 类、结构、枚举、接口和委托
- MethodDef 构造器、方法
- ParamDef 参数
- …
定义自己的特性类
1.定义一个Attribute类
模仿写一个FlagsAttribute位标识特性。
1 | public class FlagsAttribute : System.Attribute { |
2.限制特性的应用范围
希望特性只能用于枚举类型,需要用到System.AttributeUsage类的实例,该类是微软定义的用于限制特性定义范围的特性。
1 | [] |
2.5.了解一下System.AttributeUsage
1 | // 类大致定义 |
对于使用例,稍微讲一下:
DerivedType类 和它的 DoSomething方法 都被视为 [Tasty],因为他们都在应用范围内且Inherited = true,意味着可被继承。但是Serializable设置为不可被继承,所以DerivedType没有继承到父类的[Serializable]。
3.构造器
一般来说特性类就当正常类定义就行了,不过构造器比较特殊:
a.特性类构造器的入参可供选择的数据类型并不多:bool,char,byte,SByte,Int16,UInt16,Int32,UInt32,Int64,UInt64,Single,Double,String,Type,Object或枚举类型。以及上述类型的一维0基数组。如果不遵守,是通不过编译的 “不是有效的特性参数类型”。
b.特性类构造器有2种参数,一种是构造方法定义的指定参数,还有一种是增强型构造器语法所指定的值。当然无论哪种都得遵守1中的要求,演示如下:
1 | internal class TastyAttribute : Attribute |
c.我们怎么理解定制特性?它是类的实例,被序列化成驻留在元数据中的字节流。运行时可对元数据中的字节进行反序列化,从而构造出类的实例。真实情况中的元数据会稍微复杂点,构造器的参数会序列化成 “字段1 字段1类型ID 字段2 字段2类型ID…” 这样的字符串。
运用自己的特性类
光应用特性类没用
仅仅定义+应用自制的特性类没有用,只能在元数据中生成一堆额外数据罢了。
那怎么有用呢?比如特性[Flags]用于枚举类型,之所以能让ToString的方法产生行为变化,是因为ToString方法会在运行时检查自己操作的枚举类型是否关联了[Flags]特性元数据。
所以,方法会在运行时检查操作的数据是否关联了特性元数据,至于检测用的是反射技术。
检测定制特性
微软在反射插件System.Reflection.CustomAttributeExtensions提供了3个静态拓展方法来扫描托管模块的元数据,执行字符串比较来定位指定的定制特性类的位置:
| 方法名称 | 说明 |
|---|---|
| IsDefined | 如果至少有一个指定的Attribute派生类的实例与目标关联就返回true。效率很高因为不需要反序列化构造特性类的实例。 |
| GetCustomAttributes | 返回应用于目标的指定特性实例的集合;如果没有,就返回null。一般该方法用于AllowMultiple为true的特性。 |
| GetCustomAttribute | 返回应用于目标的指定特性的实例。实例使用编译时指定的参数、字段和属性,反序列化元数据获得并构造;如果没有,就返回null;如果有目标应用指定特性的多个实例,就抛出System.Reflection.AmbiguousMatchException异常。一般该方法用于AllowMultiple为false的特性。 |
在System.Reflection命名空间提供了很多类允许检查模块的元数据(也就是上述方法),包括Assembly、Module、ParameterInfo、MemberInfo、Type、MethodInfo、ConstructorInfo、FieldInfo、EventInfo、PropertyInfo及其各自的*Builder类。
用起特性类
了解前面理论之后,特性[Flags]的用法大概就会这么写:
1 | // Enum的ToString实现 |
比较特性类
特性类之间的比较通过Equals和Match两个虚方法。
System.Attribute重写了Object的Equals方法,Match默认实现就是直接调用Equals,具体比较逻辑如下:
- 先比较两个实例的类型,不一致返回false。
- 再用反射比较两个特性实例中的字段值(为每个字段都调用Equals),所有字段匹配返回true;否则false。
但是既然是虚方法,自然可以重写自定义,这里重写一个Match的实现为判断是否是子集。
1 | // 特性用标志位枚举类 |
不创建实例的检测定制特性方法
前面是调用了Attribute.GetCustomAttributes方法,这些方法会在内部调用特性类的构造器并set属性。
利用CustomAttributeData类,比如CustomAttributeData.GetCustomAttributes方法,可以不实际调用构造器与set属性,来安全获得预想状态的实例属性等,而实际上并没有真的创建实例。
1 | [] |
介绍一下GetCustomAttributes方法,它返回包裹了所有特性数据的列表,特性用类CustomAttributeData来包裹,它的属性:
- AttributeType:该特性的类型
- Constructor:已初始化过的自定义属性的构造函数
- ConstructorArguments:所使用 构造器 中的参数们(注意无法获取参数名字)
- NamedArguments:所使用 特性增强构造器 的参数们(就是命名指定的那些参数,可以获取到参数名字)
条件特性类
ConditionalAttribute
条件特性类,说的就是特性System.Disgnostics.ConditionalAttribute。将此特性应用于自定义的定制特性,该定制特性就能根据环境宏来判断是否真正应用特性类并生成其元数据。当然不止是运用于定制特性,应用于方法等也是一样有效的。使用起来有点类似于**#if**。
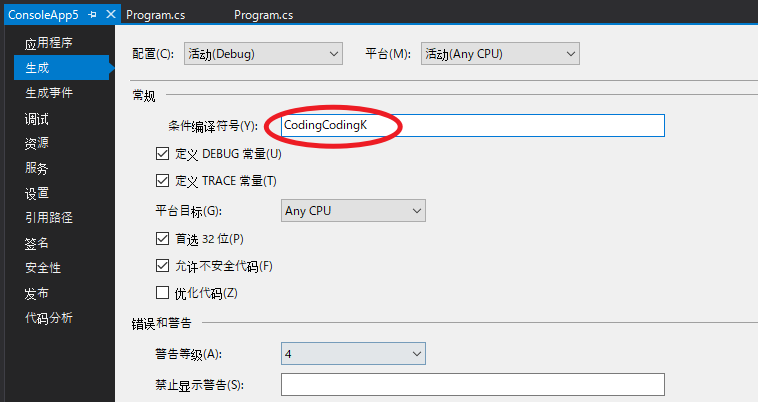
调用方法是,宏定义 或者 #define,两者是一样的含义,都是在定义编译时常量。
#define方法展示:
1 |
|
宏定义方法展示:
最后,网上有篇文章说ConditionalAttribute和#if方法使用只是类似而不是完全一致,是因为方法定义和方法调用如果在2个不同的程序集内,那么就点不同了:ConditionalAttribute是根据调用地点的程序集内有没有定义宏来选择生成代码的,而#if像上面这样写是根据方法定义地点的程序集内有没有定义宏来判断的。
我个人是觉得…其实也可以把#if写到调用方法的地方,那样两者使用的效果可以说一样了。嘛…
大章19:可null值类型
可null值类型 结构
问题由来
由于各类系统或软件之间定义的类型并不能一一配对,比如java中的java.util.Date类是引用类型,所以该类型的变量能为null;但CLR的System.DateTime是值类型,永远不能为null。
为了解决这个问题,微软在CLR中引入了可空值类型的概念,先看一下System.Nullable<T>结构来理解。
System.Nullable
1 | [] |
这段用来理解是够了,看.NET源码也确实是这么写的,自己实例化却发现null不了,很尴尬。TODO 估计是哪里漏了理解,以后再补上。
C#对可空值类型的支持
语法简化
C#允许使用T?来等价替代Nullable<T>。
1 | int? x = null; |
操作符
基本上有一个操作数是null,就直接返回null。如果操作数都不为null,那操作符计算方式与非null值类型相同。
CLR对可null类型的特殊处理
可null类型的装箱
Nullable<T>毕竟还是值类型,所以将其传给一个接收Object的方法时就得为其装箱。但是其为null时为一个null装箱很奇怪。所以CLR对可null类型的装箱多作了些手段:
- 判断是否是null,如果是,就不装箱直接返回null。
- 如果不是null,就取出值,并装箱返回。
可null类型的拆箱
如果已装箱值类型的引用是null,那么CLR会将Nullable<T>的值设为null。
1 | Object o = 5; // 创建已装箱的int |
Nullable.GetType
对Nullable<T>执行GetType(),CLR会“撒谎”说类型是T,而不是Nullable<T>。
1 | int32? x = 6; |
调用接口方法
编译器提供了更简洁的语法:
1 | int? n = 5; |
其他:空接合操作符
null-coalescing operator
空接合操作符(null-coalescing operator),即**??操作符**。它要获取两个操作数,如果左边的操作数不为null,就返回左,否则就返回右。

