
C#精要 - 常用数据结构篇
数组
最基本的数组类型。
真实类型
所有数组类型都隐式从System.Array抽象类派生,System.Array又从Object派生,所以数组都是引用类型。Array实现了IEnumerable、ICollection、IList接口。
特点
在内存中是连续存储的,所以它的索引速度非常快。
初始化
在new的时候,就必须指定它的Length大小。
数组单个元素的类型:
如果是值类型比如Int32,就会在托管堆上分配100个未装箱Int32所需的内存块,并给每个Int32实例都附上default值0;
如果是引用类型比如Control,就会在托管堆上分配50个Control引用的内存块,并给每个引用都附上null。
扩容
无法动态扩容,只能手动调用接口Array.Resize (ref T[] array, int newSize)。
内部创建新数组,使用Array.Copy将原数组拷贝到新数组中,再修改传入指针指向新数组。如果新Length还不如原数组Length大,会采用新Length,多的直接截断不要了。
查找
接口Array.Find (T[] array, Predicate<T> match)。传进去的match是一个签名为“参数为T返回值为bool”的委托,也就是一个比较器。
1 | for (int index = 0; index < array.Length; ++index) |
说实话很麻烦,还不如自己遍历。
ArrayList
在数组的基础上加入了动态扩容的概念,因此插入数据更方便了。
真实类型
实现了接口 IList、ICollection、IEnumerable、ICloneable。
而内部的数据其实还是用一个object[ ]来装,字段名是items。没错可以理解ArrayList为对Array的包装。
特点
虽然比数组多了很多快捷操作接口,但是内部用object[ ],这导致会频繁发生拆装箱、且类型非常不安全导致你可以塞各种类型到一个ArrayList里。
初始化
在new ArrayList()中可以指定容量大小,也可以不指定。
如果不指定,那就将内部items数组设置为ArrayList.emptyArray,一个定义好的定数,实际就是 new object[0]。
如果指定,那就是new object[capacity]。
扩容
引入动态扩容,调用接口ArrayList.Add (object val)即可。
先说结论,如果容量为0则设置为4,否则一旦触发扩容就翻倍,也就是二倍扩容。扩容方式就是新建数组替换items。
1 | private void EnsureCapacity(int min) |
插入
接口ArrayList.Insert (int index, object val)
也就是判断一下 size+1 是否触发动态扩容,然后把index之后的数组值用Array.Copy拷贝到index+1起始位置,然后更新数组index的值。
1 | Array.Copy((Array) this._items, index, (Array) this._items, index + 1, this._size - index); |
查找
接口ArrayList.IndexOf (object value)
全遍历。内部for循环遍历,通过obj.Equals(value)比对罢了。
移除
接口ArrayList.Remove (object obj)
先用ArrayList.IndexOf查找到index,然后调用ArrayList.RemoveAt。
RemoveAt内部用了Array.Copy,把 index+1 之后的数组值拷贝到index起始位置,那么原来位于index的值就没了,且数组最后一位会是一个废数据,给它赋null。
1 | Array.Copy((Array) this._items, index + 1, (Array) this._items, index, this._size - index); |
List
在ArrayList的基础上,加入了泛型的概念。类型是List<T>,又叫泛型List。
真实类型
实现接口:IList
内部维持的是一个泛型数组,T[] _items;。
特点
使用泛型,完美解决了ArrayList的拆装箱问题。
初始化
和ArrayList一样,可以指定可以不指定,不指定就给item赋值new T[0]。
扩容
和ArrayList一摸一样的初始为4,后续二倍扩容。
插入、查找、移除
没啥好看的,和前面一样,没有优化。
接口public T Find (Predicate<T> match)就是传入bool比较器,和Array的一样。接口IndexOf也是直接调用了Array自己的IndexOf,找不到就返回-1。
linq
linq拓展方法接口FirstOrDefault内部利用迭代器foreach遍历+bool比较器。
linq拓展方法接口Where内部利用迭代器,返回一个新的List指针(浅拷贝)。
散列表、哈希
在看哈希表、字典这两个类型前,必须掌握的基础数据结构。
在看之前
在.Net 模仿java 的过程中 抛弃了 HashMap ,所以以后再去面试.Net的时候当别人问你HashTable 和HashMap 的区别的时候,请告诉他,C#.Net 中 没有HashMap。同时C#中也没有Java中的TreeMap和TreeSet(即底层是由红黑树实现的数据结构)。
哈希函数
哈希函数是单向映射,因为一个Key只可以映射出一个hashCode,但是一个hashCode却可以被多个Key映射到(这就叫哈希冲突,要我们去解决的)。
1、直接寻址法:取keyword或者keyword的某个线性函数值为散列地址,即H(key)=key或者H(key)=a·key+b,当中a和b为常数(这样的散列函数叫做自身函数)。这个的应用就是,比如我们世界地图的掩码,直接用坐标x*1000+坐标y,得到key。
2、数字分析法:找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。分析一组数据,比方一组员工的出生年月日,这时,我们发现出生年月日的前几位数字大体相同,这种话,出现冲突的几率就会非常大,可是我们发现年月日的后几位表示月份和详细日期的数字区别非常大,假设用后面的数字来构造散列地址,则冲突几率就会明显减少。
3、平方取中法:取keyword平方后的中间几位作为散列地址。
4、折叠法:将keyword切割成位数同样的几部分,最后一部分分数能够不同,然后取这及部分的叠加和(去除进位)作为散列地址。
5、随机数法:选择一随机函数,取keyword的随机值作为散列地址,通常适用于keyword长度不同的场合。
6、除留余数法:取keyword被某个不大于散列表表长m的数p除后所得的余数为散列地址。即H(key)=key MOP p , p<=m。不仅能够对keyword直接取模,也可在折叠、平方取中等运算后取模,对p的选择非常重要,一般取素数或m,若p选的不好,容易产生碰撞。
C#散列表
建立一个确定的对应关系,使得每个key值都和一个地址一一对应。
- 存储记录时,通过 散列函数+key值 计算记录的散列地址,并用该地址存储记录。
- 查找记录时,通过同样的 散列函数+key值 计算记录的散列地址,并访问该记录。
上述的只是完美散列表,理论存在。但是 .NET 的 GetHashCode 方法返回的是Int32,也就是一一对应就只能有最多2^32个key值。但实际肯定不止这么点情况(比如key你可以用Int64),那么会出现问题:多个key值通过算法映射出来的HashCode是相同的,这叫做哈希冲突。
如何解决、减少哈希冲突就成了性能瓶颈。
C#解决哈希冲突
Hashtable:开放定址法(尝试的第一个单元被占了,那么就尝试下一个空单元)。
Dictionary:拉链法/链地址法(将所有key取哈希码相同的记录存储在同一线性链表)。
其他:再哈希法(冲突后再用其他哈希函数哈希,直到不冲突)…
为什么哈希表长要取质数?
.net解决哈希冲突:扩容、取质数(质数也叫素数)。
扩容部分在下面哈希表里再阐述,有一个词叫因子。
那为什么哈希表长要取质数?因为表长也就是容量是拿来求模的,如果和被取模的数有公因子,会导致同模的数(也就是冲突的数)之间有更多规律(存在公因子),而现实中我们的 数据源、哈希函数 往往就是有一定的关系比如取长运算就是存在公因子2。那么结果就是,冲突很可能更频繁,当然并不是一定的具体得看你的数据源和哈希函数实现。
举例:
默认长度设置为6,则2的倍数(这里不提6自己的倍数毕竟质数也一样)的整数将固定散列在0、2、4这几个数内;3的倍数将固定散布在0、3这几个数内。 此时,GetHashCode你可能写成取一系列运算之后*2,那么结果是2、4、6、8、10、12…这样的数,他们取模后分别是2、4、0、2、4、0…,这种 GetHashCode + 表长 实现下的哈希散列表,冲突的概率就非常之大。而换成7这样的质数,取模后是2、4、6、1、3、5…有改进了对吧?
自己避免哈希冲突
开发者自己想避免哈希冲突,在.net里就是设计更好的散列表也就是设计更好的GetHashCode,使映射出来的int32值尽可能不重合。
哈希表
这里只指.net提供的Hashtable类型。又称哈希表、散列表。机制关键字是2倍质数扩容、装填因子确定装载数、双重散列法(属于开放定址法)这3个要点。
https://blog.csdn.net/exiaojiu/article/details/51206024
https://www.cnblogs.com/millionsmultiplication/p/9409290.html
真实类型
内部数据是哈希桶,key-value对均为object类型,还有一个hash_coll是哈希码。
数据存在数组buckets里。
1 | private Hashtable.bucket[] buckets; |
特点
使用双重散列法,查找内存的时间复杂度为常数级。key-val类型是object,因此类型并不安全。
装填因子
装填因子(loadFactor)是 装载数/哈希表长。它决定了装载数。值越小,表长越大也就是内存损耗更大,但是哈希冲突更少。
1 | this.loadsize = (int) ((double) this.loadFactor * (double) newsize); // 装载数 是被 装填因子 所控制的。newsize是由buckets.Length取得的质数。 |
加载因子是用户可以控制的,范围是0.1f ~ 1,默认是1。在Hashtable的构造函数中可以输入。
装填因子默认取0.72,是微软认为的最佳性能默认值。
最后,装填因子 = 加载因子*装填因子的范围是0.072 ~ 0.72,默认是0.72。
装载数
装载数loadsize,装载数比桶数小。
当装满的桶数count超过装载数时会发生扩容,扩容后装载数随之更新(具体看“插入”)。
更新公式:loadsize = 装填因子 * 桶数bullets.Length(质数)
双重散列法⭐
双重散列法是开放地址法中最好的方法之一。
简单说就是有2个哈希函数,第一个哈希函数算出key的直接映射值(seed),第二个哈希函数算出冲突时使用的增量(incr)。
1 | private uint InitHash(Object key, int hashsize, out uint seed, out uint incr) { |
取好了2个seed、incr两个数据之后,第一次会去找 bucketNumber = seed % buckets.Length 的值,如果冲突再找 bucketNumber + incr) % buckets.Length的值,直到匹配。
注意!注意!注意!上面说的 bucketNumber = seed % buckets.Length ,这很重要,这是哈希桶映射的核心,毕竟算出来的hashCode比buckets.Length(桶数)大太常见了,所以需要取模。这意味着扩容后, buckets.Length发生改变,buckets内部全体都需要重新排列。
初始化
可以输入加载因子和容量,默认的加载因子是1。
初始化时,**loadFactor = 0.72f * 加载因子(0.1f ~ 1)**。容量则最小为3(最小质数)。
扩容
首先将冲突数occupancy归零,创建新buckets,然后开始拷贝旧数据。
1.创建新buckets。那它的数组长度(桶数)怎么确定?
如果是常规扩容(不是因为冲突数超过了预装载量),就会去质数表里找一个最小的、大于等于 bullets长度 * 2 的质数作为新的bullets长度。质数表:HashHelpers里的一个枚举数组,是个并不连续的质数表,从3开始一共有72个。
如果是冲突扩容(冲突数超过了预装载量),就按照目前bullets长度进行拷贝旧数据操作。所以实际并没有扩容,只做了拷贝旧数据操作,应该是因为冲突太多希望重新排列一次数据。
2.拷贝旧数据。并不是简单的复制粘贴,而是遍历buckets数组、利用putEntry重新添加元素。putEntry是Hashtable的内部插值方法,仍然是双重散列法插。为什么不直接复制粘贴?很简单,因为buckets.Length(桶数)变了,那么所有的hashCode % buckets.Length的下标位置都得变。
大规模的putEntry终究是高时耗的,所以新建hashtable时最好选择一个稍大的容量,避免频繁扩容。
插入
Insert的内部操作分三个步骤:
1.判断key是否为空,如果空,哈希函数是无法计算地址的。
2.判断bullets实际使用条目数count(装满的桶数) 是否大于等于装载数,如果满足,哈希表需要扩容为原来装载数的2倍以上(从质数表里取);如果前一条不满足,则继续判断冲突数是否大于装载数,如果大于,则扩容。
3.接着在循环体内按照双重散列法寻找对应键值的桶并为对应键值的桶赋值。
查找
就是双重散列法。
移除
核心就是按照双重散列法寻找对应键值的桶后将桶变成空桶,然后count–(实际桶数)。
字典
Dictionary<TKey, TValue>泛型字典,解决Hashtable拆装箱。机制关键字是buckets+entries双数组、拉链法基础上改进、FreeList单链表这3个要点。
https://www.cnblogs.com/xiaomowang/
真实类型
这里哈希桶主要用来进行Hash碰撞(和Hashtable类不一样),Entry数组用来存储字典的内容,并且标识下一个元素的位置。
Entry数组是一个单链表。
KeyCollection、ValueCollection内部真实数据就是这个字典本身。然后KeyCollection和ValueCollection实现了一些常用接口,比如GetEnumerator返回的时候帮你把字典的迭代返回类型KeyValuePair<TKey, TValue>转换成TKey / TValue了再返回。
1 | private int[] buckets; // Hash桶,桶的下标是hashCode,桶内的int值是entries单链表的链下标 |
特点
字典和哈希表不一样!它内部可不是用双重散列法了。
初始化
如果不指定capacity,那么就基本什么也不做。内部方法Initialize (capacity)的调用,则会在第一次Add时进行。
如果指定了capacity,那么就会调用内部方法Initialize (capacity)。
1.首先,去质数表找一个大于等于capacity的质数(和Hashtable一样),作为哈希桶容量。
2.new哈希桶,全部赋值-1。
3.new Entry数组。
1 | private void Initialize(int capacity) |
扩容
扩容时机
1.非冲突扩容。触发时机是Entries实际使用 == Entries元素总数。
2.冲突扩容(其实不是扩容,是重排序,但不用一个一个插入)
扩容方式
先建新Buckets、Entries数组。新数组大小没有装填因子的概念,就是二倍扩容找质数罢了。
再直接拷贝Entries数组,直接Array.Copy(和Hashtable不一样)。
// 如果是冲突重排序,那么此时还需要把Entries里所有的元素重新计算一遍HashCode(当然我觉得没啥用)。
最后遍历Entries,对每个元素都进行重新映射赋值Buckets、重建链表:
1 | for (int index1 = 0; index1 < this.count; ++index1) |
插入
Add接口,会直接调用内部方法Insert。
1.首先检测是不是没有执行初始化(new时没有输入capacity),没的话就执行Initialize (0)。
2.和下图一样,先哈希 + 位与intMax + 取模映射到Buckets下标,
如果发现对应的桶内装的是-1,那就是没冲突过的哈希,不用处理;
如果发现对应的桶内装的不是-1,那就是冲突了的哈希,就取找对应Entries里的元素,这个元素就是链头,获取它的Next,一直往后找,找到链尾(Next == -1),记录出冲突数num。
3.有个叫FreeList的单链表,它本身是个int(具体看“移除”节)。总之,会先去FreeList找碎片形式的Entry位,如果FreeList是空的(FreeCount == 0 )就直接往后找从没用过的Entry位(具体就是用count++)。
找到新的Entry位后,如果没冲突过就将其Next设置成-1,如果冲突过就将它设置为新的链头。转化为代码很简单,就是:
1 | Entries[没用过的Entry位].Next = Buckets[hashCode]; // Buckets[hashCode]默认是-1,否则是链头 |
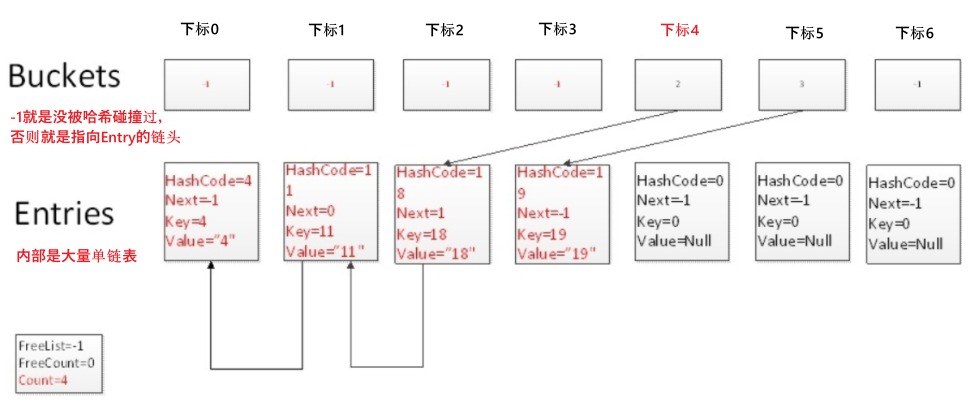
查找
找起来就挺容易的,毕竟处理操作都在插入、移除的时候做好了。简单来说就是链地址法。
移除
Remove接口。
分2步,第一步是根据Key算出哈希映射值,找到对应桶中指向的Entry结点。根据清空进行 更新链头or清空桶 / 更新链表。
1 | if (桶内指向的是链头) |
第二步,把上面去掉的Entry节点清空内容后,作为FreeList的新链头:
1 | this.entries[index3].hashCode = -1; |
哈希表vs字典
解决冲突的方法不同。Hashtable用的是基于开放地址法的双重散列法;Dictionary用的是拉链法。
内部数组数量不同。Hashtable只用1个数组;Dictionary用2个数组。
桶装的东西不同。内部都用到了桶的概念,但是Hashtable的桶装的是数据实体;Dictionary桶装的是int,存放着实体数组Entries的链头。
都是二倍质数扩容,但是扩容的时机不同。Hashtable多了装填因子、装载数的概念;Dictionary就直接比对count和Entries.Length。
线程安全字典
ConcurrentDictionary。
1 | private volatile ConcurrentDictionary<TKey, TValue>.Tables m_tables; |
网上很多对比ConcurrentDictionary和Dictionary+Lock效率的文章,说大规模情况下ConcurrentDictionary读快、Dictionary+Lock写快。所以更多会选择Dictionary+Lock的方案。
迭代器
IEnumerable和IEnumerator区别
IEnumerable可迭代的是一个声明式的接口,声明实现该接口的类就是“可迭代的”,但并没用说明如何实现迭代器(iterator)。
IEnumerator迭代器是一个实现式的接口,它提供了具体怎么实现“可迭代的”。
我们自己写代码,一般给类实现IEnumerable接口即可。
IEnumerable:
1 | public interface IEnumerable<out T> : IEnumerable |
IEnumerator:
1 | public interface IEnumerator<out T> : IDisposable, IEnumerator |
foreach支持
用foreach遍历,并不需要实现IEnumerable接口,只要显式的实现IEnumerator GetEnumberator 无参方法即可。
foreach本质也是个语法糖,编译器帮你获取对象迭代器然后while(MoveNext){ Current }:
1 | IEnumerator enumerator = test.GetEnumerator(); |
yield使用
普通使用迭代器的话,无效代码太多了。下面就是一个我选择最简单实现的例子,可以正常foreach。
1 | public class Test |
但是c#引入了yield语法糖,实现就容易多了。
可以在方法,属性 和 索引器中使用 yield 来实现迭代器。
1 | public class Test |
yiled解析
yield语法糖,其实是编译器帮你在你定义的类中,生成了一个新的 IEnumerator实现类。接口需要的MoveNext、Reset、Current编译器都帮你用默认方式实现好了。
而 yield return; yield break; 语法糖自动生成的代码,就是在MoveNext里写case。
1 | private bool MoveNext() |
红黑树
// TODO

