
CLR Via C#个人笔记3 - 基元类型、引用类型和值类型
大章5:值类型与引用类型
基元类型
什么是基元类型?
- 有些数据类型太常用了,为了方便程序员书写,C#编译器允许代码以简化语法来操纵。这些编译器直接支持的数据类型叫做基元类型(primitive type)。
- 注意一下,一般国人说的类型是指值类型和引用类型的分类,和这里的类型不是一个意思。
比如以下的代码
1 | int a = 0; |
他们4个生成的IL代码是完全一样的。
基元类型一览
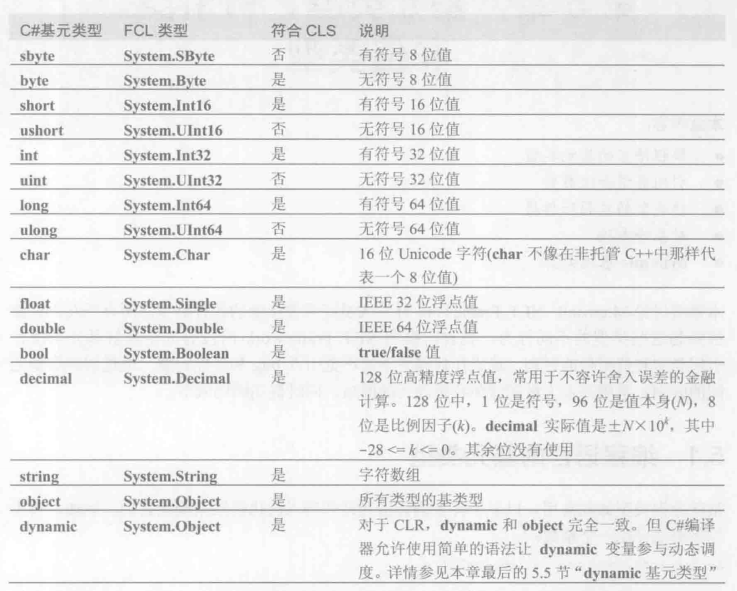
基元类型的映射
- string和String都是直接映射System.String,所以他们是完全一样的,所以基元类型的本质是映射到FCL(.NET 的 Framework Class Library)类型。
- 不同语言编译器,对于映射的处理不同,比如C#会将long映射到System.Int64而C++是映射Int32。
- 隐式转换,C#只会在转换安全的情况下才允许。所谓安全,就是说不会发生数据丢失的情况,比如从低精到高精。显式转换可以允许数据丢失,C#总是会选择将数据截断,而不是取上取整。
基元类型的溢出检查
比如以下代码就会溢出:
1 | Byte b = 100; |
溢出处理根据不同编译器,处理结果是不同的。C++不将溢出视为错误,允许值回滚(wrap),程序会继续执行;而C#允许程序员自己选择最合适的处理,是否检查溢出抛错。
C#溢出检查默认关闭,意味着我们编译生成的IL代码是无溢出检查版本,代码能更快运行,但要求开发人员能保证不发生溢出。如果执行的是溢出检查版本,运算执行时会稍慢一些,且检查不过关会抛出OverflowException异常。
- C#全局开启溢出检查:编译时使用 /checked+编译器开关。
- C#局部开启溢出检查:用 checked 和 unchecked 关键字
- 比较好的控制溢出方案是,对于不希望溢出的核心数据,放在checked中抛异常catch住,然后再catch里得体恢复数据。
此外,decimal类型特别特殊,结构和编译器处理不同,上面的checked和unchecked不会起效,一定会抛出OverflowException异常。
引用类型和值类型
CLR允许2种类型:引用类型和值类型。
我们要阐明两者的区别。首先说一下引用类型。
① 内存分配差异
引用类型
5个特点
- 内存必须从托管堆分配。
- C#的new操作符返回对象内存地址——即指向对象数据的内存地址。
- 堆上分配的每个对象都有一些额外成员,这些额外成员必须初始化。
- 对象中的其它字节(为字段而设)总是设为0。
- 从托管堆分配对象时,可能强制执行一次GC。
可以看到,引用类型的开销非常之大,如果全是引用类型,那么程序的性能会显著下降。为了提升简单常用类型的性能,CLR提供了“值类型”的轻量级类型。比较一下。
vs 值类型
- 值类型实例一般在线程栈上分配(当然也可以作为字段嵌入引用类型的对象中,那就在堆上了)。
- 在代表值类型的实例中包含的是实例本身的字段,而不是引用or指针。
- 值类型的实例不受GC垃圾回收器的控制,意思是不会引起GC,从而有效减少了GC回数。
- 未装箱的值类型不会在堆上分配,意味着一旦定义了该类型的实例得方法不再活动,为其分配的存储空间会立刻被释放。
微软DOCS会清楚指出哪些类是引用类型,哪些是值类型。叫“类”的是引用类型,叫“结构”、“枚举”的是值类型。
继续研究会发现,所有“结构”都是抽象类型System.ValueType的直接派生类,System.ValueType本身又直接从System.Object派生。所有“枚举”都从System.Enum抽象类型派生,System.Enum本身有直接从System.ValueType派生。简单来说就是:
- System.Enum << System.ValueType << System.Object
值类型是密封类,目的是为了防止被作为基类,当然可以选择给值类型实现多个接口。
② 两者使用分配流程
没啥好说的,总结一下,具体的看图吧。
- 值类型,真实的值放在线程栈上;赋值就是深拷贝,我们自己想写值类型用
struct关键字。 - 引用类型,线程栈上只持有指针,真实的值放在托管堆上,哪怕类里面有值类型字段,值类型字段也会被放在托管堆上;赋值只是浅拷贝,线程栈上给赋个指针,我们自己写用
class关键字。 - 还有就是,虽然①里说了,值类型拥有减少GC得好处,但是值类型需要逐位复制,所以期望其类型得实例比较小(小于16字节)。而且struct是密封的,意味着值类型不能作为基类,对代码复用不友好。

③ 值类型的装箱和拆箱
什么是装箱?
- 一种机制。将值类型转换成引用类型的就叫做装箱机制。
1 | struct Point{ |
装箱时发生了什么?
换句话说也就是将值类型转换成引用类型时发生了什么。
- 在托管堆中分配内存。分配的内存量时值类型各字段所需的内存量 + 托管堆所有对象都有的两个额外成员(类型对象指针 和 同步块索引)所需的内存量。
- 值类型的字段复制到新分配的堆内存中。
- 返回对象地址。
结束这套流程后,返回的是地址,所以变成引用类型了。
C#编译器检测到上述代码是向要求引用类型的方法传递值类型,所以自动生成IL代码对对象进行装箱。具体发生的事看下面。
C#编译器做 装箱 时具体干了什么?
检测到上述情况后,会把当前存在于Point值类型实例p中的字段复制到新分配的对象中,再把这个对象的引用返回到Add方法作为入参继续执行。外部只知道p是引用类型,可以被继续引用标记,且已装箱的值类型的生存期超过了未装箱值类型的生存期。
什么是拆箱?
- 拆箱不是直接将装箱的过程倒过来!它的代价比装箱小得多。
- 拆箱只是指获取指针的过程,获取的是指向包含在一个引用对象中的原始值类型(也就是字段,比如上面的x、y字段)的指针。
1 | // 假定要用以下代码获取ArrayList的第一个元素 |
拆箱时发生了什么?
- 获取已装箱Point对象中的各个字段的地址。(这个叫拆箱)
- 将字段包含的值从堆中复制到栈的值类型实例中。(拆箱操作经常紧接着一次字段复制)
注意,以上情况中,如果引用的对象不是所需值类型的已装箱实例,会抛出InvalidCastException异常。比如,
1 | public static void Main(){ |
从逻辑上说,完全能把o从Int32转换成Int16,但是不行,只能转换为最初未装箱时的值类型。
C#编译器做 拆箱 时具体干了什么?
其实和上面讲述的是一样的。
- 先对o拆箱,生成一条IL指令,获取已装箱对象中的各个字段的地址。
- 再复制,生成一条IL指令,将这些字段从堆复制到栈变量中。
简单的拆装箱优化
- 一些常用方法有很多重载,根据入参的不同选择最合适的入参,减少拆装需求
1 | public static void Main(){ |
- 同样的类多次装箱or拆箱,可以合并为一次
1 | // v是个Int32型 |
未装箱值类型vs引用类型
未装箱值类型更轻:
- 不再托管堆上分配。
- 没有每个对象都有的额外成员:“类型对象指针” 和 “同步块索引”。
因为没有同步块索引,所以无法用lock等。
除此之外,调用一些 未装箱值类型 自己的方法或者重写的方法时是不需要装箱的(比如在struct定义中重写public override String ToString() );
而由 System.Object 所定义的方法(非虚继承),那么就需要装箱,比如p.GetType();
或者你重写的方法里,还调用了基类型的方法,那么就要装箱。
最后聊一下
已装箱过的值类型,再拆箱更改其字段的话只是改了拆箱后的栈字段,在堆上的已装箱值类型数据是不会被修改的。
1 | Point p = new Point(1,1); // Point是struct类 |
另外,可以用接口欺骗C#,具体的就不说了,可以看书P122。
对象相等性与同一性
同一性 identity
这两个概念都是基于比较对象的概念,比如System.Object类提供的Equals虚方法,是这样的
1 | public class Object{ |
很显然,这不能称之为比较两者是否相等,而是在比较两者指针是否指向同一个堆中对象,这叫做同一性(identity)。
由于是虚方法可以被重写,所以真的想比较 同一性 的话,会选择静态方法 ReferenceEquals。
相等性 equality
因为System.Object类提供的Equals方法比较混淆,所以System.ValueType就重写了Object的Equals方法:
- 如果obj实参为null,就返回false
- 如果this和obj实参引用不同类型的对象(不是对象指针,是之前提过的每个类都会持有自己的类型!),就返回false
- 针对类型定义的每个实例字段,进行一一比较(调用字段的Equals方法)。任何字段不相等,就返回false
- 返回true!ValueType的Equals方法不调用父类Object的Equals方法
上述3中的比较,是通过反射完成的。
重写自己的Equals
如果想要重写Equals,需要满足下面4个特性:
- Equals必须自反:x.Equals(x)肯定返回true;
- Equals必须对称:x.Equals(y)与y.Equals(x)返回相同的值;
- Equals必须可传递:x.Equals(y)为true、y.Equals(z)也为true,那么x.Equals(z)一定为true
- Equals必须一致
且我们实际上想写自己的Equals的时候,会这样:
- 实现IEquatable
接口 - 重载==和!=操作符
如果还需要排序,需要手动实现:
- IComparable接口的CompareTo方法
- IComparable
接口的类型安全的CompareTo方法 - 重载比较操作符(<、<=、>、>=),在内部调用类型安全的CompareTo方法
对象哈希码
在按照上面重写Equals时会发现,编译器会提示你要求一起重写Object.GetHasCode()方法。包括上面的类型安全实现接口IEquatableGetHasCode()方法。
这是因为由于在System.Collections.Hastable类型、System.Collections.Generic.Dictionary类型以及一些其他集合实现中,要求两个对象必须具有相同哈希码才被视为相等。
所以重写Equals就必须重写GetHashCode以保持对象哈希码算法与相等性算法保持一致。
哈希码是什么
这里介绍一下哈希码。
向集合添加key-val对,首先需要获取key的哈希码。哈希码指出key-val对要存储到哪个哈希桶(bucket)中。
集合需要查找键时,会获取指定键对象的哈希码,该哈希码标识了即将要以顺序方式搜索的哈希桶,将会在桶里找对应的key。
所以按照上述算法,如果修改了一个键值对的key让它没有存在于正确的哈希桶中,那么就永远找不到它了。所以正确修改key的方法是先删后加。
重写自己的GetHashCode
以下规则,全文背诵:
- 这个算法要提供良好的随机分布,使哈希表获得最佳性能
- 一般不要直接用Object或者ValueType的GetHashCode方法,因为他们性能都不高
- 算法至少使用一个实例字段
- 理想状态下,算法使用的字段应不可变,在构造时初始化后就不再变是最好的
- 算法执行速度尽量快
- 包含相同值得不同对象应返回相同哈希码
- 不要将哈希码持久化,比如记录进数据库,因为GetHashCode的算法很可能被更新
举个例子,上面提到的Point类可以这么写:
1 | internal sealed class Point{ |
dynamic基元类型
dynamic是什么
dynamic关键字,我的理解,是一个动态决定类型的var。他是为了方便程序员简化代码而推出的不安全类型。具体如下:
1 | dynamic value; |
动态决定类型,比起纯安全类型,可以省去大量代码。
编译器在为dynamic生成特殊IL代码来描述所需要的操作,这种特殊代码叫做payload(有效载荷)。运行时,payload代码根据dynamic引用的对象的实际类型来决定具体执行操作。
实际上,dynamic声明一个变量,编译器会把它当作Object来用,IL代码里也就是object,一样的,直到变量被赋值确定了具体类型。
再来一个简化代码例子来理解dynamic:
1 | // 利用反射调用String.Contains方法 |
dynamic调用vs反射调用
这个要看IL实现,具体的不多深究。总的来说,
- dynamic调用方法是用到0级缓存,会比反射快一些。
- 代价是需要用到运行时绑定器(runtime binder类),它存在于Microsoft.CSharp.dll程序集中,所以必须将该程序集加载到AppDomain中(程序集会进内存),且在payload代码执行时生成动态代码(会进程序集也就是内存里),使得会损害应用程序的性能,增大内存消耗。
- dynamic无法调用到类型静态方法,只能调用实例方法。
所以,即使上述代码用dynamic写很整洁,但如果需要用dynamic的地方很少,那一般还是会选择反射实现。

