
书籍笔记 - 程序是怎样跑起来的(硬件软件交互理解)
CPU
CPU可直接执行的“机器码”,到底能处理什么?
简单来说分为4种,
数据传送指令:用于寄存器、内存、外围设备之间进行数据读写的操作。也就是读写操作。
运算指令:用累加寄存器执行算术运算、逻辑运算、比较运算和位移运算。
跳转指令:实现条件分支、循环、强制跳转等。其实就是个goto。
call/return指令:函数的调用 / 返回调用前的地址。和c#的函数栈桢展开是类似的。
二进制数
如何在硬件层面理解二进制、bit、byte?
像计算机的CPU和内存都是IC的一种,IC就是有很多引脚的集成电路,而每一个引脚的状态只有直流电压0V和5V,这两种。因此计算机的信息只能转化成二进制。
而**位(bit)**这个数据结构,就刚好对应了这个规律。
**字节(byte)**则是8个bit,因为内存和磁盘都是用字节为最小单位来存储、读写数据的,所以用位bit不能直接读写数据,所以都会在高位补0实现bit转byte。
而一个CPU有32位,就意味着它有32个引脚来处理信息的输入和输出,也就是说一次可以处理32位的二进制数信息。
为什么计算机内用补码来存数?(比如-1是11111111而不是10000001)
为了实现通过相加来实现减法。
补码是取反+1的结果,同样的这个结果和无符号位的原码相加结果为0。
小数
什么是浮点数?它是怎么表示小数的?
什么是浮点数?是使用符号、尾数、基数、指数这四个部分来表示小数的,形式为± m * n的e次方。符号就是±,基数n因为计算机二进制所以是2。而至于尾数m和指数n,就是根据具体数字来的,但也并不是毫无参照。
它是怎么表示小数的?
首先,分为单、双精度浮点数,它们表示范围不同,根据最为普遍的IEEE标准,单精浮点(32位)有1位符号部分、8位指数部分、23位尾数部分;双精浮点(64位)有1位符号部分、11位指数部分、52位尾数部分。

其次,对于尾数m,就像科学计数法一样,浮点数也有一种表示规则来限制诸如0.75 * 10^0、7.5 * 10^-1这种同一个数字,表示方式却不同的情况。在二进制数中,用的是“将小数点前面的值固定为1的正则表达式”。
比如1011.0011 => 0001.0110011 =>第一位固定1所以可以去掉,多表示1位 0110011000...(省略0,补齐23/52位)
最后,对于指数e,用的是EXCESS系统来表示它的正负。比如单精指数部分只有8位的情况下,最大值11111111=255,用它的一半01111111=127来记作0,比它大的是正数,比它小的是负数。指数e的表示范围从0255变为-127128。
浮点数会不准确
为什么浮点数会不准确?计算机用浮点数无法处理0.1这种转换为二进制会无尽的小数。所以会导致0.1打印输出会变成0.10000002之类的。
如何解决?一般可以不解决,因为科学近似精度已经足够高了。但如果是一些严格要求准确的领域,
方法1.可以把小数倍乘成整数来计算,计算完后再除回去。
方法2.可以使用BCD(Binary Coded Decimal)表示法,就是用4位来表示0~9的1位数字。
浮点数c#实践
在c#中尝试把一个float用二进制输出出来,比如0.75f,输出的值确实是按照1-8-23划分的:0-01111110-10000000000000000000000。但是结果是反过来的,不清楚为什么,书中用的c++是正序的。另外就是,用BitConverter.GetBytes接口转的是byte,也就是8位2进制转成10进制读得的数值,所以还需要再转回8位2进制数。
内存
如何理解内存硬件
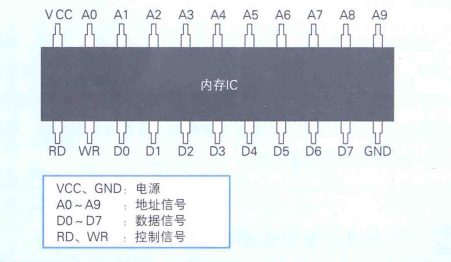
比如一个内存,其实就是一堆引脚。VCC、GND引脚是接电源的,DR、WR是控制信号用来操控读、写。
A0-A9的引脚用来表示地址,所以可以表示1024个地址;D0-D7表示数据,8位2进制,也就是1个字节B。所以这个内存的容量为1KB。
一个内存内部有大量空间去存储这些8位数据,通过地址引脚指定的地址来读写这些数据。
内存地址
1个地址指向1个字节(内存的最小单位);
32位系统一次可以读4个字节,等于其最高可表示2^32个地址数。
所以32位系统,内存上限为4GB。
内存与磁盘
CPU、内存、磁盘
1.程序保存在存储设备中,通过有序地被读出来实现运行。
2.CPU只能执行已经加载到内存中的程序。
如何理解磁盘硬件
磁盘是用扇区作为读写最小物理单位的,一个扇区为512字节。但是Windows在逻辑方面对磁盘进行读写的单位是簇,1簇可以设置为扇区整数倍,比如可以1簇=1扇区(512字节)、也可以1簇=2扇区(1KB)等等。
无论是多么小的文件,都会占用至少1簇。
磁盘缓存
磁盘访问速度 < 内存访问速度,所以会用内存映射一段磁盘数据作为缓存,如果下一次还用到的磁盘数据刚好被内存加载过,那就直接去速度更快的内存里拿数据。这叫缓存。到win98时代,由于磁盘访问速度越来越快,这种技术的提升就不是很显著了,但是这个思想也用于Web把远端服务器加载下来的数据存入磁盘中。
虚拟内存
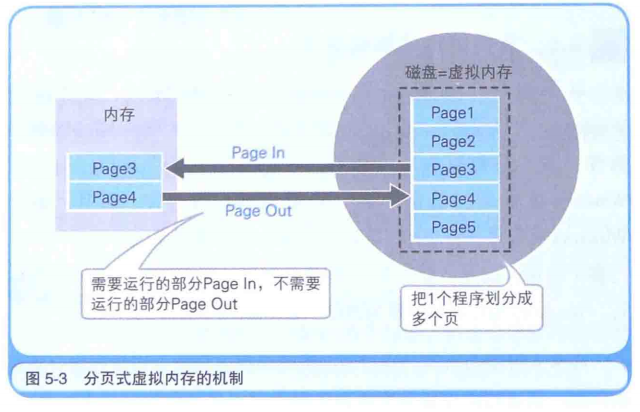
正好与磁盘缓存相对的概念,就是说划分一块磁盘区域作为假想的内存来使用。但CPU只能执行已经加载到内存中的程序,所以实际上是在把内存和磁盘中的内容不停进行置换,保持当前正在运行的程序部分有在物理内存中。而置换就涉及一个最小单位,Windows是用页为单位(一般4KB)。
压缩
就只列举一些常见的压缩算法。
文本文件:RLE压缩(文本 x 次数 的形式)、哈夫曼(权重画树、编码)压缩
图像文件:可逆压缩、不可逆压缩。
虚拟机
虚拟机是什么
因为应用是针对操作系统OS的,所以Windows应用只能在Windows系统上运行。而虚拟机就是在其他OS上,模拟Windows运行环境,来实现跨平台。
其他跨平台方式
除了虚拟机之外,还有两个方式。一个是Ports机制,是移植的意思。该机制能够结合当前运行的硬件环境来编译应用的源代码。
另一个是Java虚拟机,它其实是一种运行环境。Java在编译之后生成的不是机器码而是字节代码,然后字节代码在不同平台实现的Java虚拟机上运行,转换成本机代码。和c#一样。
编译
从程序到机器码 - 编译器
编译器把源代码转换成本地代码(本机代码),它内部仿佛有一个 源代码-本机码 的对应表,但实际上读入的源代码还需要经过语法解析、句法解析、语义解析等,才能生成本地代码。
编译器本身也是一个程序,所以也需要运行环境(比如Windows)。根据输出的目标CPU类型、输入的高级语言的不同,编译器也不同(比如Windows可用的x86系CPU的C编译器)。
生成EXE - 链接器
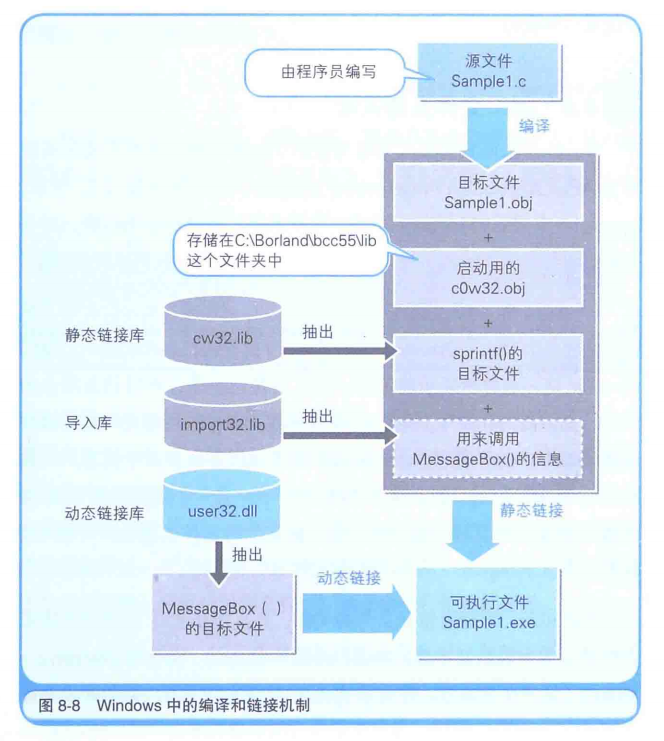
编译后的机器代码是一个obj文件(里面都是2进制数),并不能直接运行。还需要把代码中的引用其他文件的部分、和obj文件结合,生成出一个EXE文件。这就是链接。
EXE启动 - 分配内存
一个程序经过编译+链接后,生成了可执行文件EXE,但是程序源码里对函数、变量的调用都是指向内存地址的,但一个EXE文件并没有给它分配内存地址,怎么办呢?
其实,EXE文件中给变量、函数分配了虚拟的内存地址,当EXE运行时会把虚拟的内存地址转换成实际的内存地址。链接器在EXE文件的开头,追加转换内存地址所需的必要信息,这个叫做再配置信息。
当EXE运行时,还会分配额外的2块连续内存,一个是栈、一个是堆。栈用来存储函数内部临时变量,堆用来存储运行时数据以及对象。栈的内存管理代码是编译器自动生成的,而堆的内存管理是需要人为编写的,c++中用new申请、delete来释放。这就是GC。
常见编译问题
什么是编译器、什么是解释器?
两者都是把高级语言转化为机器语言的程序。编译器再运行前把源码转换成二进制可执行文件,而解释器逐条读取源码转换成机器码。
Build是什么意思?
编译+链接
DLL可以不用链接就调用到吗?
可以,通过LoadLibrary()、GetProcAddress()这些API,即使不链接导入库,也可以在程序运行时调用DLL文件中的函数。
通过汇编理解程序
什么是汇编语言?
汇编语言和本地代码是一一对应的。汇编语言是本地代码(二进制)的助记符。
汇编语言怎么看?
伪指令:负责把程序的构造以及汇编的方法指示给汇编器。伪指令proc和endp围起来的部分,表示的是函数的范围,里面的是函数执行过程。
语法结构:操作码+操作数,比如mov+内存地址
以下是x86的部分操作码、主要寄存器:
| 操作码 | 操作数 | 功能 |
|---|---|---|
| mov | A、B | 把B的值赋给A |
| and | A、B | 把A同B的值相加,并将结果赋给A |
| push | A | 把A的值存储在栈中 |
| pop | A | 从栈中读取出值,并将其赋给A |
| call | A | 调用函数A,调用时自动获取栈上对应数量的入参 |
| ret | 无 | 将处理返回到函数的调用源 |
调用函数流程:
1.先把ebp寄存器(数据领域基址寄存器)的值入栈,再把函数的入参push入栈。
//注意,栈的高位地址在下面,低位地址在上面。
2.使用call指令 + 函数名(函数指针),调用时自动获取栈上对应数量的入参。
3.清理栈,把入参销毁掉。具体是把esp的寄存器值(栈顶指针寄存器)add上 4 * 入参数。
//至于为什么是4字节,因为堆栈进行数值的输入输出时,数值的单位是4字节。
4.pop读出此时栈顶的数值,也就是1中存储的ebp寄存器值,存入ebp寄存器。执行ret返回。
//为什么把edp寄存器的值原地倒腾了一遍?因为这是c语言的规定,确保函数调用前后edp不变。
此外.函数的参数是通过栈来传递,返回值是通过寄存器返回的。
汇编实现功能
循环
使用标记 + goto标记 的 思路去做,具体助记符就不记了(先cmp再jmp)。
条件分支
一样是标记 + go标记去实现的。
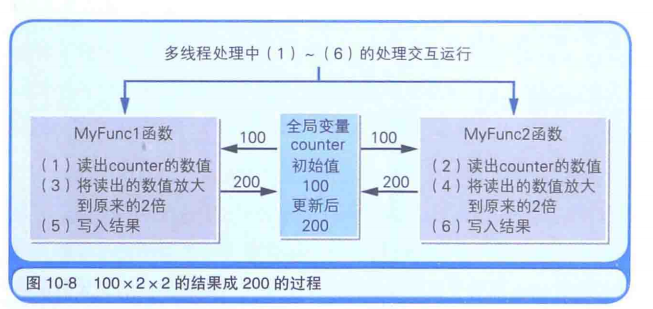
多线程问题
写2个把全局变量x2的相同的函数,再多线程分别调用1次,可能遇到结果为2倍而不是2x2倍的情况。原因如图。解决方案是用c语言中的锁定方法。
硬件控制
外围设备硬件和软件是如何实现通信的?
首先,应用与硬件无关:Windows系统下的硬件是由系统全权负责的,应用层只能通过API来通过系统调用。
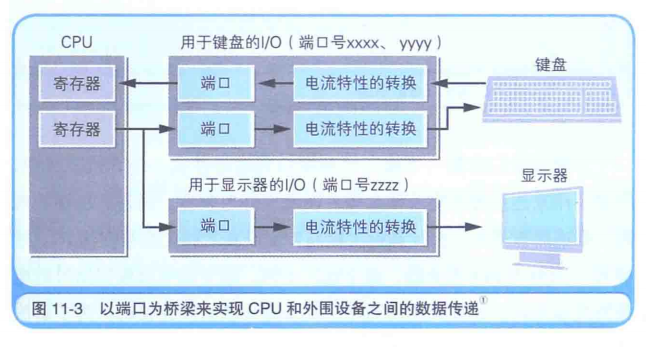
其次,硬件们是通过I/O控制器来实现和操作系统通信的:计算机有着USB等和外围设备交互的连接器,因为外围设备的电压不同、用的也是模拟信号,所以无法和硬件直接连接,需要用I/O控制器。
什么是端口:I/O控制器中由用于临时保存输入输出数据的内存,这个内存叫端口。端口是内存,也有自己的地址,叫端口号或者I/O地址。
汇编语言的IN/OUT指令,是通过端口和寄存器之间数据互换实现的:汇编中的IN/OUT助记符是实现和硬件交互的,IN指令把端口数据存储在CPU寄存器中,OUT把CPU寄存器数据存储在端口中。
外围设备硬件的中断操作IRQ
IRQ(Interrupt Request)是中断请求的意思,对应的值是0x06。
它负责把当前正在运行的主程序中断(同时把CPU所有寄存器的数值保存到栈中),然后跳转到外围设备的输入输出运行,等运行完后返回中断程序(同时恢复所有寄存器的值),继续执行。
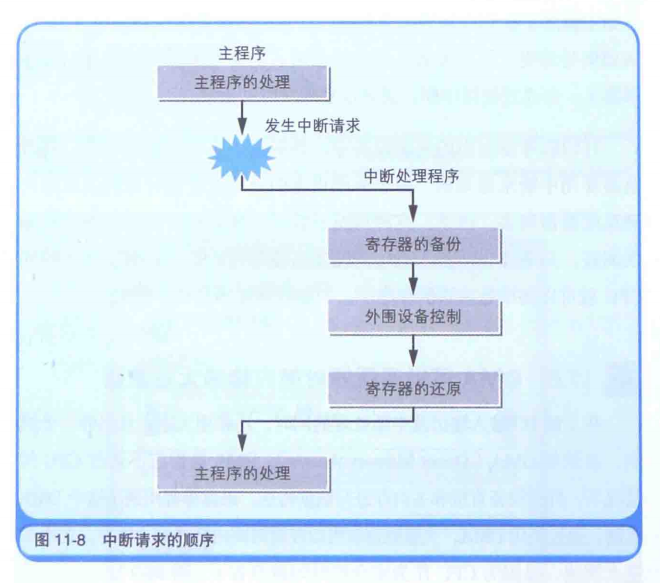
遇到诸如打印机这种操作比CPU慢很多的设备,就可以等中断请求发生时再输出数据即可;而对于实时性比较高的比如鼠标等,就可以不停轮询。
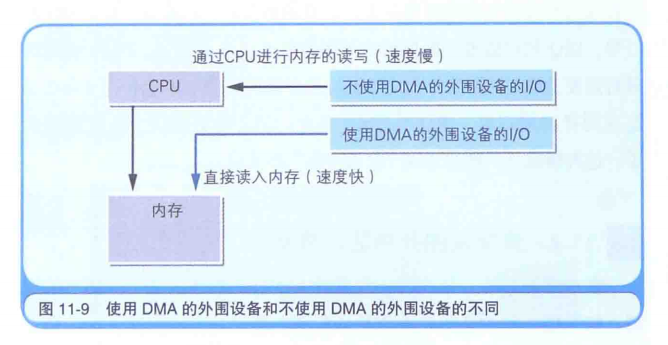
外围设备直接和内存通信DMA
像IRQ的中断,本质上还是要和CPU交互的。但是DMA(Direct Memory Access)可以不通过CPU,外围设备直接和主内存进行数据传送。这样更快。
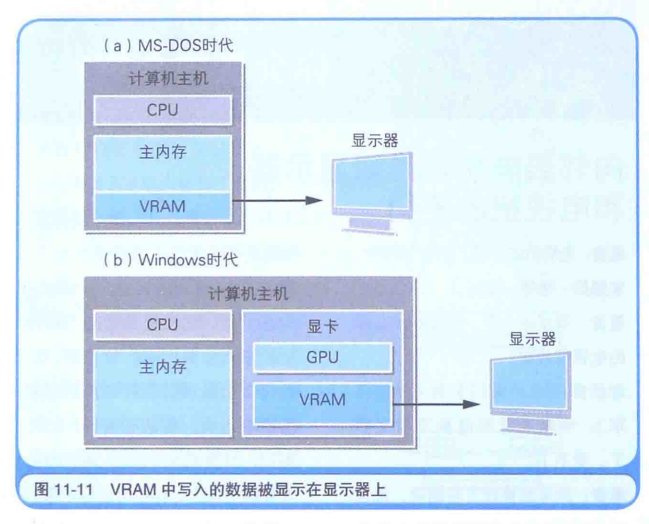
计算机图形的内存VRAM
显示器中显示的数据,一直存储在内存总,这个内存叫VRAM(Video RAM)。在程序中,只要往VRAM中写入数据,该数据就会在显示其中显示出来,此功能由操作系统或BIOS提供。
在DOS系统时代,VRAM是主内存的一部分,图形颜色只能用16种是因为这块内存太小了。而如今,显卡配有独立的VRAM内存。
计算机的随机数
线性同余法实现伪随机
很多伪随机其实就是用线性同余法的递推公式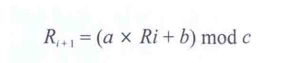
实现的。
指定了a、b、c之后,就会生成0 ~ c(不包括c)的随机数。其中Ri、a、b、c就是随机数的种子。
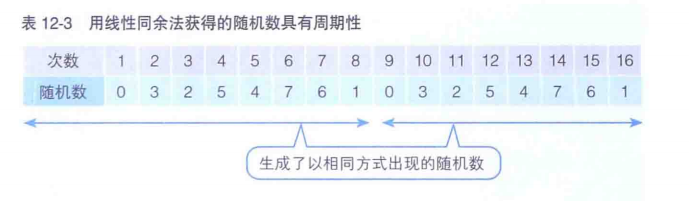
那这样为什么叫伪随机呢?因为指定好a、b、c之后的数,不停递推生成的结果是有周期性的。
C入门
数据类型
| 名称 | 长度(位长) | 精度 |
|---|---|---|
| char | 8 | -128,+127 |
| short | 16 | -32768,32767 |
| int(或者long) | 32 | -2147483648,2147483647 |
| float | 32 | 略 |
| double | 64 | 略 |
常用关键字

