
Hello Agents - 记忆与检索&RAG
记忆与检索
需求原因
局限一:无状态导致的对话遗忘
当前的大语言模型虽然强大,但设计上是无状态的。这意味着,每一次用户请求(或API调用)都是一次独立的、无关联的计算。模型本身不会自动“记住”上一次对话的内容。这带来了几个问题:
- 上下文丢失:在长对话中,早期的重要信息可能会因为上下文窗口限制而丢失
- 个性化缺失:Agent无法记住用户的偏好、习惯或特定需求
- 学习能力受限:无法从过往的成功或失败经验中学习改进
- 一致性问题:在多轮对话中可能出现前后矛盾的回答
要解决这个问题,我们的框架需要引入记忆系统。
局限二:模型内置知识的局限性
除了遗忘对话历史,LLM 的另一个核心局限在于其知识是静态的、有限的。这些知识完全来自于它的训练数据,并因此带来一系列问题:
- 知识时效性:大模型的训练数据有时间截止点,无法获取最新信息
- 专业领域知识:通用模型在特定领域的深度知识可能不足
- 事实准确性:通过检索验证,减少模型的幻觉问题
- 可解释性:提供信息来源,增强回答的可信度
为了克服这一局限,RAG技术应运而生。它的核心思想是在模型生成回答之前,先从一个外部知识库(如文档、数据库、API)中检索出最相关的信息,并将这些信息作为上下文一同提供给模型。
记忆模块
设计
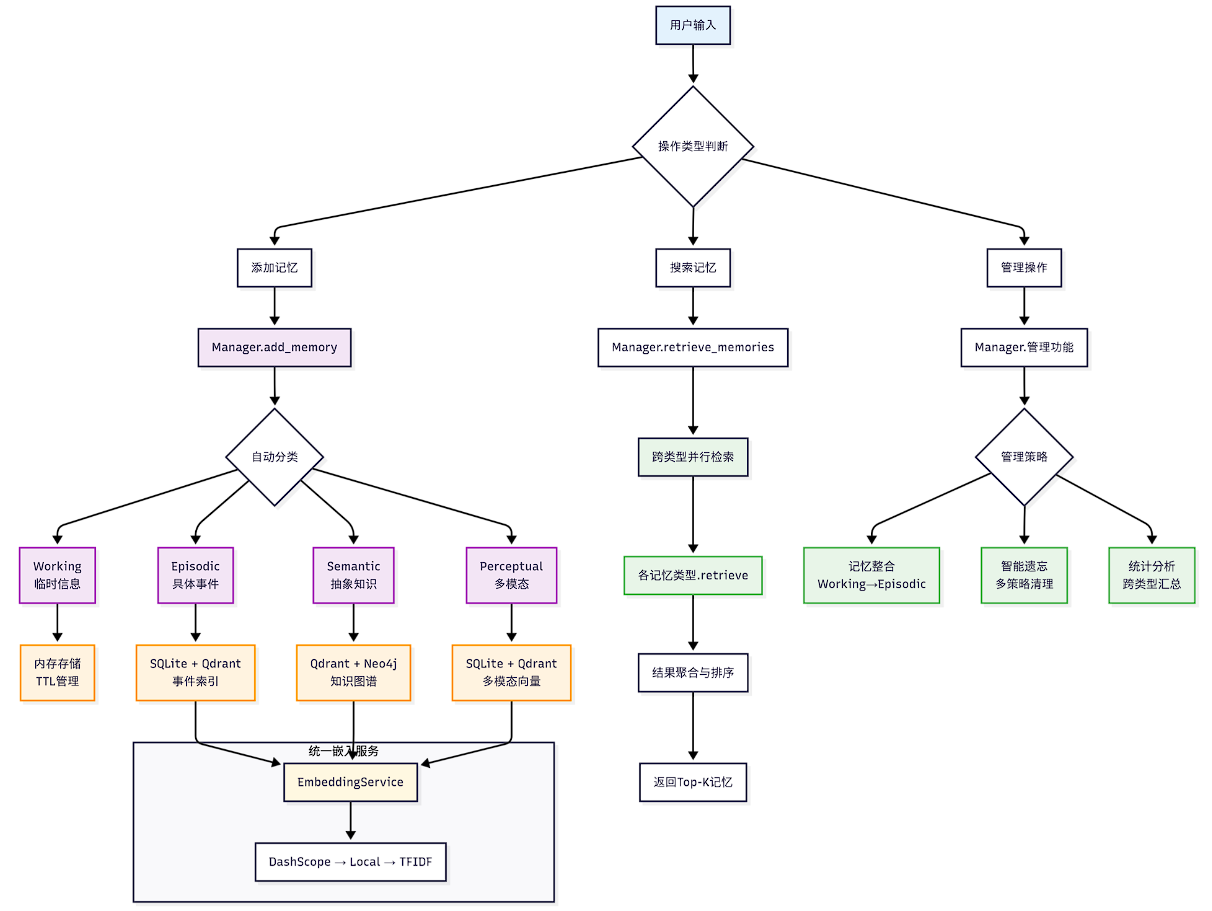
- **工作记忆 (Working Memory)**:充当短期记忆的角色,存储上下文,快速访问,限制容量(比如默认50条)。
- **情景记忆 (Episodic Memory)**:长期存储具体的交互事件和智能体的学习经历。支持按时间序列或主题进行回顾式检索。
- **语义记忆 (Semantic Memory)**:它存储的是更为抽象的知识、概念和规则。比如用户偏好、需要长期遵守的指令或者领域知识点。
- **感知记忆 (Perceptual Memory)**:专门处理图像音频,支持跨模态检索。
工作记忆
- 对memory操作的主要的方法是:
add、search、forget、consolidate(整合,短期记忆提升为长期记忆) - 工作记忆采用了纯内存存储方案,配合TTL(Time To Live)机制进行自动清理。
- 工作记忆的检索采用了混合检索策略,首先尝试使用TF-IDF向量化进行语义检索,如果失败则回退到关键词匹配。
情景记忆
情景记忆负责存储具体的事件和经历,它的设计重点在于保持事件的完整性和时间序列关系。采用了SQLite+Qdrant(向量数据库)的混合存储方案。
1) 存记忆(add)
- 把一条记忆(内容 + 时间 + 会话ID + 其他信息)打包成一个
Episode - 记录这条记忆属于哪个会话(
session_id) - 然后保存到两种地方:
- SQLite:像“表格数据库”,方便按时间、用户、会话等条件筛选
- Qdrant:像“向量库”,把文本变成向量,方便按“语义相似”搜索
2) 找记忆(retrieve)
找的时候走三步:
- 先按条件过滤(结构化过滤)
比如:只看某个时间范围、某个用户、某个会话的记忆(用 SQLite 这种结构化方式更快更准) - 再做语义搜索(向量检索)
用 Qdrant 找“意思最像”的记忆(不是关键词匹配,而是语义相似) - 最后打分排序
每条候选记忆会算一个总分,分数越高越靠前。
打分怎么来的(_calculate_episode_score)
它把三件事合起来:
- 语义相似度(最重要,占 80%)
- 时间越近越加分(占 20%)
- 重要性权重(importance 越高,整体再乘一个更大的系数)
语义记忆
它负责存储抽象的概念、规则和知识。语义记忆采用了Neo4j图数据库和Qdrant向量数据库的混合架构。简单来说,在这边做了2套数据库来供检索,1是向量数据库,2是实体/关系的知识图谱数据库。
向量&知识图谱 数据库,怎么用的?
你把一段文本/知识喂给它:
add(memory_item)
它会自动:把文本转成向量
从文本里抽取实体、关系
写入图数据库 + 向量数据库
你问一个问题:
retrieve(query, limit=5)
它会:用向量库找语义相似的记忆
用图数据库找相关实体/关系的记忆
把两边结果合并排序,取前
limit条返回
具体存储&检索代码呢?
向量部分:
1 | function add: |
知识图谱部分:
1 | function add: |
为什么要混合用?
- 只用向量:语义相近很强,但对“实体关系链”的查询不一定稳(尤其是编号、关系推理)
- 只用图谱:对实体关系很强,但对“同义改写/自然语言泛化”弱
所以它混合:
- 向量给“语义相似度”(0.7)
- 图谱给“关系相似度/推理补充”(0.3)
- 再用重要性做轻微加权
知识图谱是什么?为什么要用?
知识图谱把信息变成:
- 实体(Entity):人、产品、公司、地点、订单、功能名……
- 关系(Relation):实体之间的连接,例如:
- “用户A 购买 订单984233”
- “订单984233 包含 商品:蓝牙耳机”
- “蓝牙耳机 属于 品牌X”
- “故障 发生在 左耳”
图谱强在:不仅能找“像不像”,还能找“有没有关系”。
感知记忆
感知记忆支持文本、图像、音频等多种模态的数据存储和检索,为不同模态的数据创建独立的向量集合。
是什么
这是一个“多模态记忆库”:可以把 文本 / 图片 / 音频 等内容存起来,并在需要时按“相似”把相关内容找出来。它的关键设计是:不同模态分开存(每种模态一个独立向量库/collection),这样不会因为向量维度不同而混乱,检索也更准。
用法(怎么用)
存入:把一条记忆(内容 + 模态 + 时间 + 重要性等)交给它保存(代码里没贴 add,但逻辑就是:先编码成向量,再写入对应模态的向量库)。
检索:调用
1
retrieve(query, limit=5, query_modality=..., target_modality=..., user_id=...)
query_modality:你输入的 query 是什么模态(默认 text)target_modality:你想搜哪种模态的记忆(不填就搜同模态)user_id:只查某个用户的记忆(可选)
同模态例子:用文本去搜文本记忆。
跨模态例子:用文本描述去搜相关图片/音频(依赖“对齐到同一语义空间”的编码器)。
怎么做的(实现步骤)
- 为不同模态准备不同编码器
- 文本:
text_embedder - 图片:
CLIP模型(把图片或文本映射到和图片相关的向量空间) - 音频:
CLAP模型(把音频或文本映射到和音频相关的向量空间)
- 为每个模态建一个独立的向量集合(Qdrant collections)
perceptual_text(文本向量,维度 = text 的 dim)perceptual_image(图片向量,维度 = image 的 dim)perceptual_audio(音频向量,维度 = audio 的 dim)
这样做的目的:不同模态向量维度不同,必须分开存。
检索流程(retrieve)
先把 query 用对应模态的编码器转成向量:
_encode_data(query, query_modality)选择要搜的向量库(同模态或指定 target 模态)
在 Qdrant 里做相似度搜索(并加一些过滤条件:user_id、modality 等)
对结果重新打分排序:
语义相似度(占 80%)
时间越近越加分(占 20%,用指数衰减模拟遗忘)
重要性再乘一个权重(让重要内容略靠前)
返回前
limit条
RAG系统
什么是RAG
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和文本生成的技术。它的核心思想是:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答。
一个完整的RAG应用流程主要分为两大核心环节。
- 在数据准备阶段,系统通过数据提取、文本分割和向量化,将外部知识构建成一个可检索的数据库。
- 随后在应用阶段,系统会响应用户的提问,从数据库中检索相关信息,将其注入Prompt,并最终驱动大语言模型生成答案。
工作模式
- 数据处理流程:处理和存储知识文档,在这里我们采取工具
Markitdown,设计思路是将传入的一切外部知识源统一转化为Markdown格式进行处理。 - 查询与生成流程:根据查询检索相关信息并生成回答。
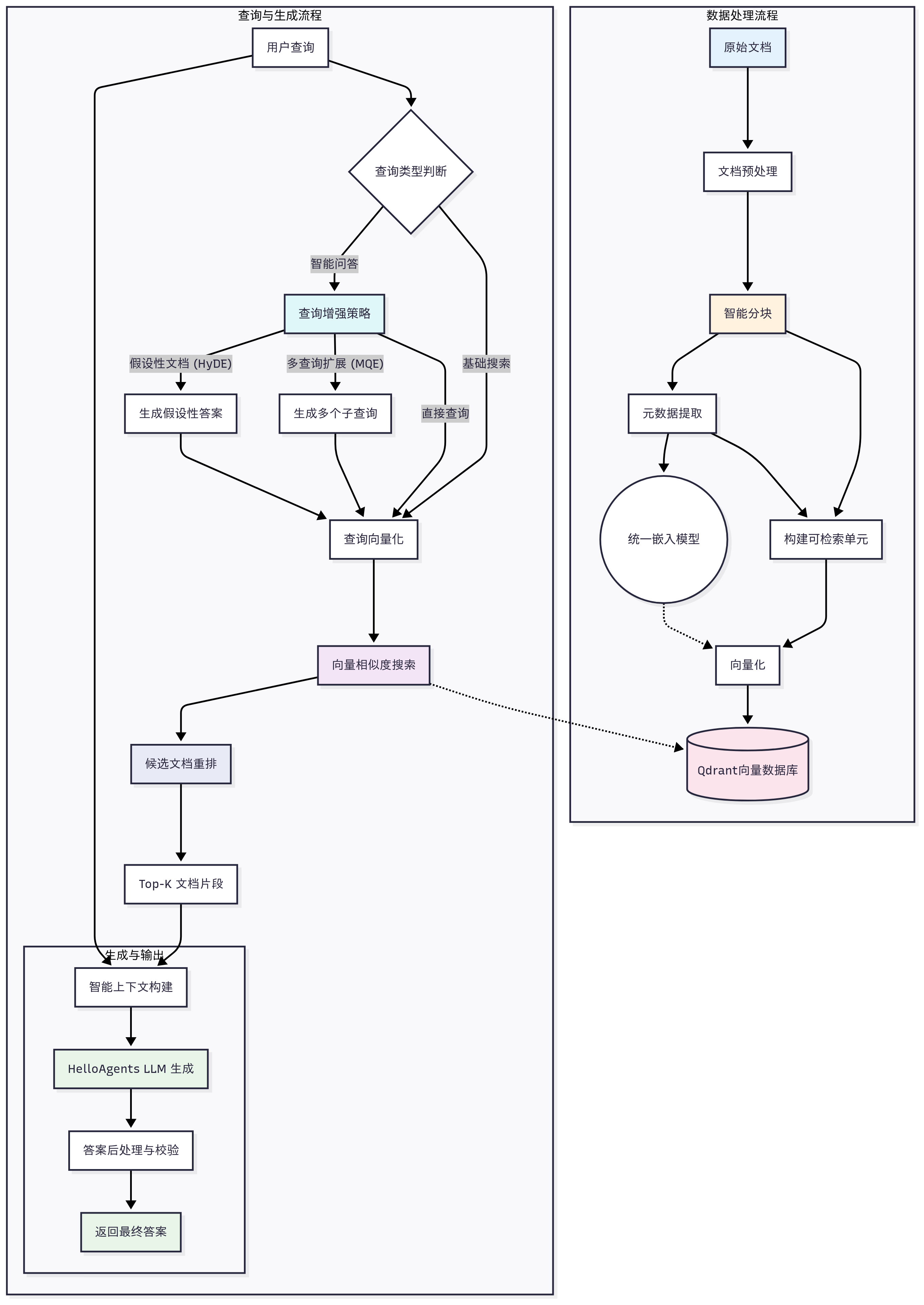
RAG 存储pipeline ☆
- 转换格式:把所有不同类型的文件(JPG,MP3…) 全部通过
MarkItDown转换形成markdown格式文件。 - 智能分块:
- 使用markdown的标题(#、##)、和段落,进行语义分割
- 根据Token的数量,把这些分割好的段落切成块(chunk)
- 下一个块的开头,会有上一个块结尾的内容,这叫做**重叠()**,目的是为了保持块之间的上下文连接
- 统一嵌入与向量存储:把文本块转换为向量,存储在向量数据库中。这边嵌入(embedding)说的就是转成高维度的向量模型。
高级查询策略
(1)多查询扩展(MQE)
例如,”如何学习Python”可以扩展为”Python入门教程”、”Python学习方法”、”Python编程指南”等多个查询。
多查询扩展(Multi-Query Expansion)是一种通过生成语义等价的多样化查询来提高检索召回率的技术。这种方法的核心洞察是:同一个问题可以有多种不同的表述方式,而不同的表述可能匹配到不同的相关文档。
MQE的优势在于它能够自动理解用户查询的多种可能含义,特别是对于模糊查询或专业术语查询效果显著。
系统使用LLM生成扩展查询,确保扩展的多样性和语义相关性。
(2)假设文档嵌入(HyDE)
假设文档嵌入(Hypothetical Document Embeddings,HyDE)是一种创新的检索技术,它的核心思想是”用答案找答案”。
HyDE通过让LLM先生成一个假设性的答案段落,然后用这个答案段落去检索真实文档,从而缩小了查询和文档之间的语义鸿沟。因为答案与答案比起问题与答案来说,拥有更加接近的语义空间。
(3)扩展检索框架
将MQE和HyDE两种策略整合到统一的扩展检索框架中。扩展检索的核心机制是**”扩展-检索-合并”**三步流程。先用多种搜索方法(比如上面的MQE+HyDE),检索到的文档进池,然后去重+分数排序,获得最后的Top-K检索结果。
优化点:对于需要高召回率的场景可以同时启用两种策略,对于性能敏感的场景可以只使用基础检索。
使用案例
- 把一些pdf等资料,预先调用RAGTool的方法,来触发完整处理流程(MarkItDown转换、增强处理、智能分块、向量化存储)。
- 把“这个文档加载成功”加到情景记忆模块中。
