
Hello Agents - 构建Agent
Agent 经典范式
为了更好地组织智能体的“思考”与“行动”过程,业界涌现出了多种经典的架构范式。在本章中,我们将聚焦于其中最具代表性的三种,并一步步从零实现它们:
- ReAct (Reasoning and Acting): 一种将“思考”和“行动”紧密结合的范式,让智能体边想边做,动态调整。
- Plan-and-Solve: 一种“三思而后行”的范式,智能体首先生成一个完整的行动计划,然后严格执行。
- Reflection: 一种赋予智能体“反思”能力的范式,通过自我批判和修正来优化结果。
ReAct
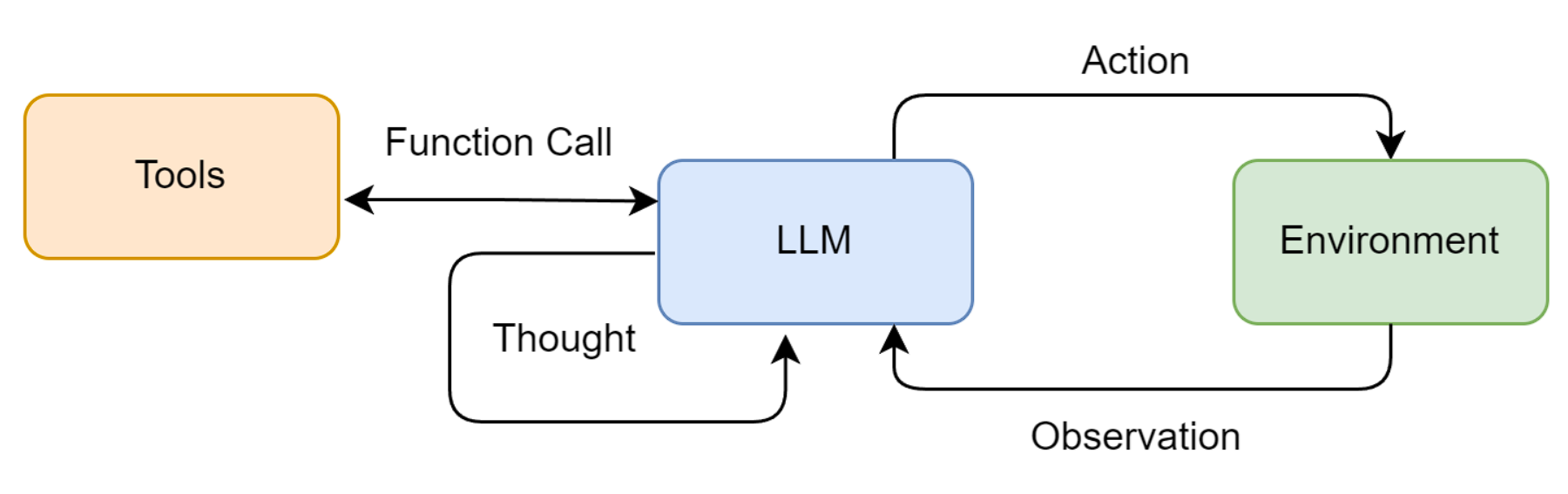
基本模式
思考与行动是相辅相成的,思考指导行动,而行动的结果又反过来修正思考。
具体执行分成3步:
- Thought (思考): 这是智能体的“内心独白”。它会分析当前情况、分解任务、制定下一步计划,或者反思上一步的结果。
- Action (行动): 这是智能体决定采取的具体动作,通常是调用一个外部工具,例如
Search['华为最新款手机']。 - Observation (观察): 这是执行
Action后从外部工具返回的结果,例如搜索结果的摘要或API的返回值。
智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。这个过程形成了一个强大的协同效应:推理使得行动更具目的性,而行动则为推理提供了事实依据。
代码架构
核心是[工具,工具描述]。
- 角色定义: “你是一个有能力调用外部工具的智能助手”,设定了LLM的角色。
- **工具清单 (
{tools})**: 告知LLM它有哪些可用的“手脚”。 - **格式规约 (
Thought/Action)**: 这是最重要的部分,它强制LLM的输出具有结构性,使我们能通过代码精确解析其意图。 - **动态上下文 (
{question}/{history})**: 将用户的原始问题和不断累积的交互历史注入,让LLM基于完整的上下文进行决策。每次的observation也会扔到上下文里。
优缺点、优化技巧☆
优点:
- 高可解释性:步骤透明。通过
Thought链,能让我们清楚看到每一步AI的理解、操作。 - 动态规划和纠错能力:每一次都会把observation放到上下文,里面包含了外界新信息,因此可以动态调整&修正搜索词。
- 工具协同能力:结构清晰,工具非常好写。
缺点:
- 非常依赖LLM能力:因为决策由LLM的
Thought环节来决定,导致错误会产生错误的规划和错误的 Tool Function 的输入值。 - 执行效率:循序渐进,串行思考,导致每次都会多次调用LLM,消耗比较大。
- 脆弱性:提示词模板(工具的解释?)的改动会非常影响输出结果,导致变化会大。
- 陷入局部最优:步进式的决策模式,容易因为眼前的
observation来决策,导致缺乏长远规划。
优化技巧:
- 检查完整提示词
- 分析原始输出
- 验证工具输入输出
- 调整提示词的示例
- 尝试不同模型或者参数
Plan and solve
- 规划阶段 (Planning Phase): 首先,智能体会接收用户的完整问题。它的第一个任务不是直接去解决问题或调用工具,而是将问题分解,并制定出一个清晰、分步骤的行动计划。这个计划本身就是一次大语言模型的调用产物。
- 执行阶段 (Solving Phase): 在获得完整的计划后,智能体进入执行阶段。它会严格按照计划中的步骤,逐一执行。每一步的执行都可能是一次独立的 LLM 调用,或者是对上一步结果的加工处理,直到计划中的所有步骤都完成,最终得出答案。
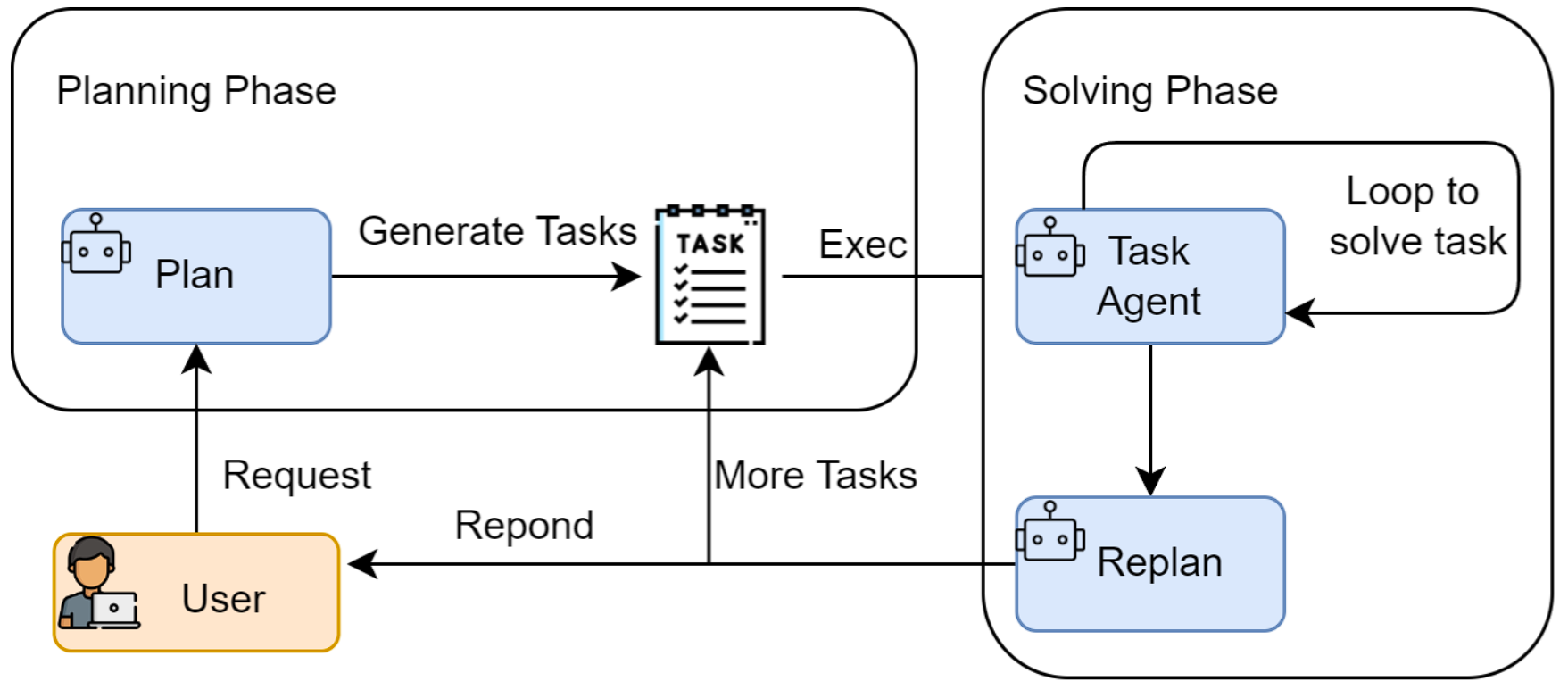
规划器
使用prompt来控制LLM输出一个plan,里面包含了所有执行步骤。
执行器&状态管理
执行器的目标不是分解问题,而是在已有上下文的基础上,专注解决当前这一个步骤。因此,prompt 需要包含以下关键信息:
- 原始问题: 确保模型始终了解最终目标。
- 完整计划: 让模型了解当前步骤在整个任务中的位置。
- 历史步骤与结果: 提供至今为止已经完成的工作,作为当前步骤的直接输入。
- 当前步骤: 明确指示模型现在需要解决哪一个具体任务。
状态管理:指的是维护一个历史记录(状态),也就是上下文,慢慢添加。
1 | # 更新历史记录,为下一步做准备,在for循环里 |
Reflection
为智能体引入一种 事后(post-hoc)的自我校正循环,使其能够审视自己的工作,发现不足,并进行自我迭代优化。核心工作流程:执行 -> 反思 -> 优化 。
- **执行 (Execution)**:首先,智能体使用我们熟悉的方法(如 ReAct 或 Plan-and-Solve)尝试完成任务,生成一个初步的解决方案或行动轨迹。这可以看作是“初稿”。
- 反思 (Reflection):接着,智能体进入反思阶段。它会调用一个独立的、或者带有特殊提示词的大语言模型实例,来扮演一个“评审员”的角色。这个“评审员”会审视第一步生成的“初稿”,并从多个维度进行评估,例如:
- 事实性错误:是否存在与常识或已知事实相悖的内容?
- 逻辑漏洞:推理过程是否存在不连贯或矛盾之处?
- 效率问题:是否有更直接、更简洁的路径来完成任务?
- 遗漏信息:是否忽略了问题的某些关键约束或方面? 根据评估,它会生成一段结构化的**反馈 (Feedback)**,指出具体的问题所在和改进建议。
- **优化 (Refinement)**:最后,智能体将“初稿”和“反馈”作为新的上下文,再次调用大语言模型,要求它根据反馈内容对初稿进行修正,生成一个更完善的“修订稿”。
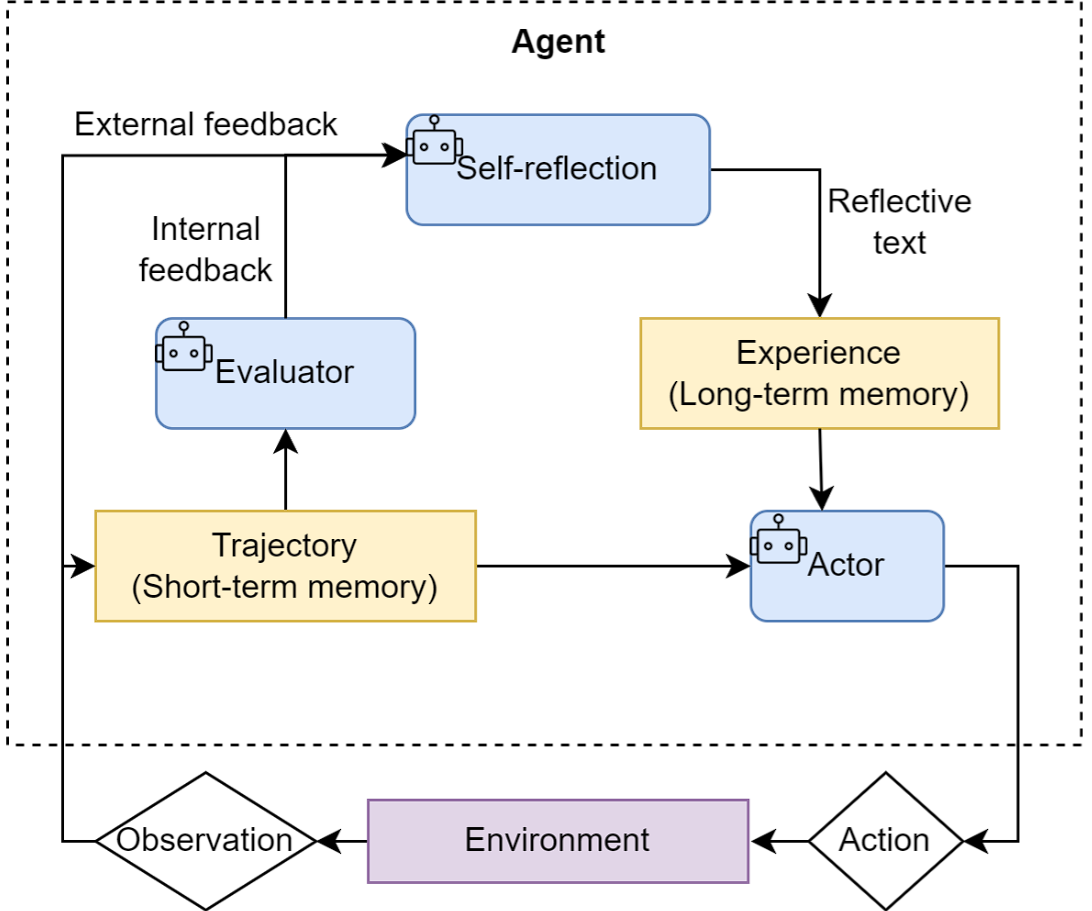
实现
- 初始执行提示词 (Execution Prompt) :这是智能体首次尝试解决问题的提示词,内容相对直接,只要求模型完成指定任务。
- 反思提示词 (Reflection Prompt) :这个提示词是 Reflection 机制的灵魂。它指示模型扮演“代码评审员”的角色,对上一轮生成的代码进行批判性分析,并提供具体的、可操作的反馈。
- 优化提示词 (Refinement Prompt) :当收到反馈后,这个提示词将引导模型根据反馈内容,对原有代码进行修正和优化。
优缺点
优点:
- 解决方案质量提升:迭代,提升结果质量
- 鲁棒性和可靠性增强:因为有内部自我纠错循环
缺点:
- 开销增大:模型多次迭代,意味着需要花费更多的 token调用
- 任务延迟提高:因为reflection是串行运行的,多迭代多花时间
- 提示工程复杂度上升:需要对 “执行、反思、优化” 有不同的高效提示词
三者比较
- ReAct: 通过“思考-行动-观察”的动态循环,它成功地利用搜索引擎回答了自身知识库无法覆盖的实时性问题。其核心优势在于环境适应性和动态纠错能力。
- Plan-and-Solve: 它将复杂的任务分解为清晰的步骤,然后逐一执行。其核心优势在于结构性和稳定性,特别适合处理逻辑路径确定、内部推理密集的任务。
- Reflection (自我反思与迭代): 其核心价值在于能显著提升解决方案的质量,适用于对结果的准确性和可靠性有极高要求的场景。

Agent框架

使用场景总结
- 深度协作和创造性思维:CAMEL 对于创作特别有用处,代码少提示多,重设计。
- 严格流程控制:对于需要精确步骤控制的任务,LangGraph 的图结构更合适。
- 大规模并发:AgentScope 的消息驱动架构在高并发场景下更有优势。
- 复杂决策树:AutoGen 的群聊模式在多方决策场景下更加灵活。
AutoGen
思路&架构
多个Agent扮演专家,自我对话式完成任务。
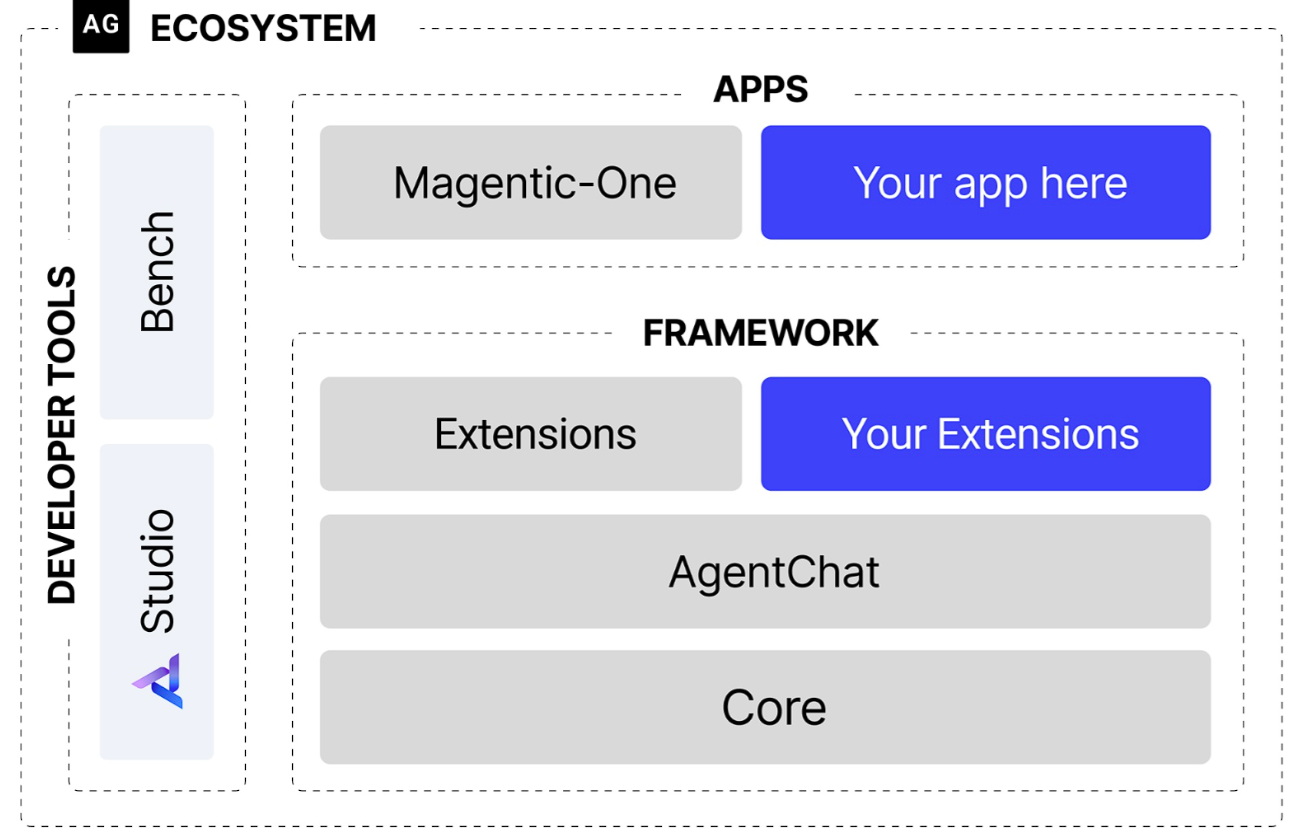
有不同角色
- AssistantAgent (助理智能体): 这是任务的主要解决者,其核心是封装了一个大型语言模型(LLM)。它的职责是根据对话历史生成富有逻辑和知识的回复,例如提出计划、撰写文章或编写代码。通过不同的系统消息(System Message),我们可以为其赋予不同的“专家”角色。
- UserProxyAgent (用户代理智能体): 这是 AutoGen 中功能独特的组件。它扮演着双重角色:既是人类用户的“代言人”,负责发起任务和传达意图;又是一个可靠的“执行器”,可以配置为执行代码或调用工具,并将结果反馈给其他智能体。这种设计清晰地区分了“思考”(由
AssistantAgent完成)与“行动”。
执行流程
- 轮询群聊 (RoundRobinGroupChat): 这是一种明确的、顺序化的对话协调机制。它会让参与的智能体按照预定义的顺序依次发言。这种模式非常适用于流程固定的任务,例如一个典型的软件开发流程:产品经理先提出需求,然后工程师编写代码,最后由代码审查员进行检查。
- 工作流:
- 首先,创建一个
RoundRobinGroupChat实例,并将所有参与协作的智能体(如产品经理、工程师等)加入其中。 - 当一个任务开始时,群聊会按照预设的顺序,依次激活相应的智能体。
- 被选中的智能体根据当前的对话上下文进行响应。
- 群聊将新的回复加入对话历史,并激活下一个智能体。
- 这个过程会持续进行,直到达到最大对话轮次或满足预设的终止条件。
- 首先,创建一个
优缺点
易于设计,职责匹配的方式贴近人类社会
对于流程化任务,有清晰的执行步骤
LLM不确定性,可能陷入错误分支或者陷入循环。
整体串行,调试困难
AgentScope
思路&架构
AgentScope 就是一个完整的”智能体操作系统”,为开发者提供了从开发、测试到部署的全生命周期支持。与许多框架采用的继承式设计不同,AgentScope 选择了组合式架构和消息驱动模式。
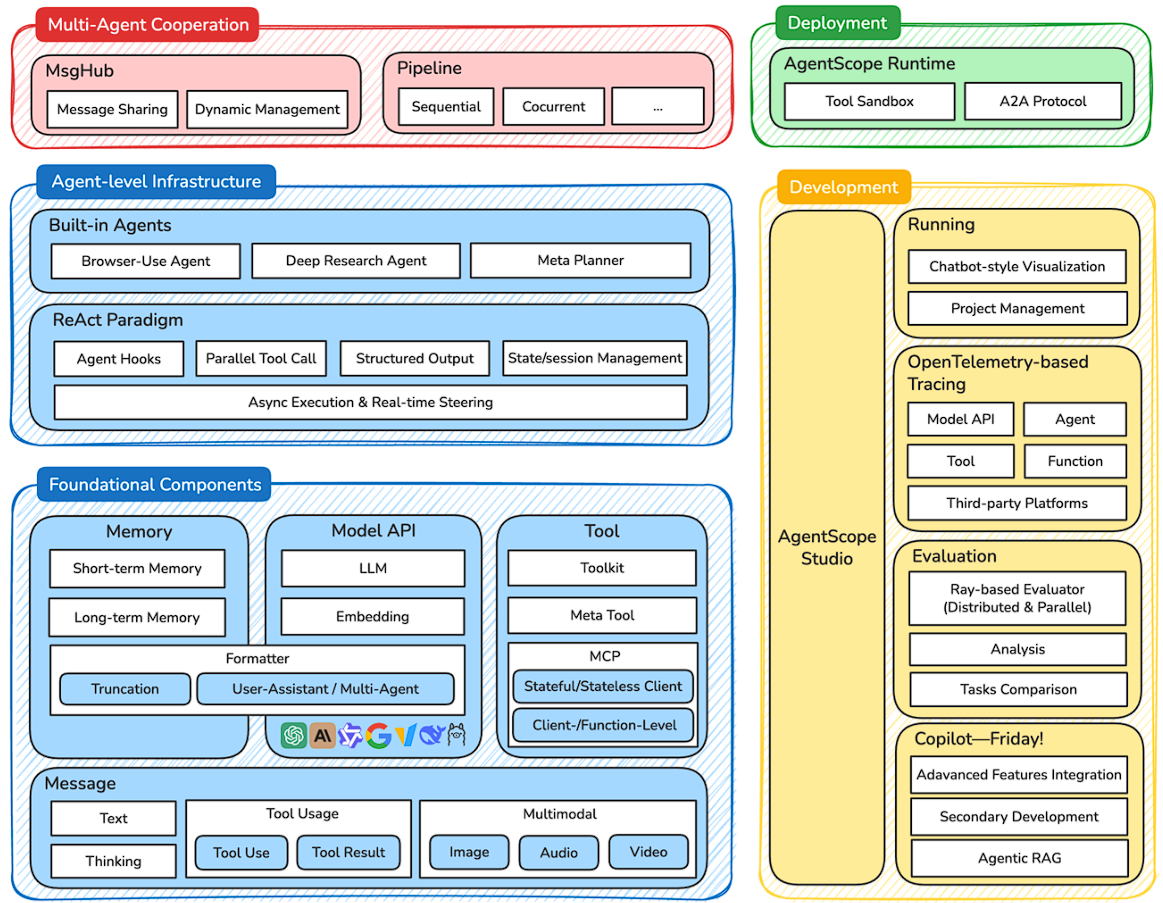
消息驱动
AgentScope 的核心创新在于其消息驱动架构。在这个架构中,所有的智能体交互都被抽象为消息的发送和接收,而不是传统的函数调用。
1 | from agentscope.message import Msg |
好处:
- 异步解耦: 消息的发送方和接收方在时间上解耦,无需相互等待,天然支持高并发场景。
- 位置透明: 智能体无需关心另一个智能体是在本地进程还是在远程服务器上,消息系统会自动处理路由。
- 可观测性: 每一条消息都可以被记录、追踪和分析,极大地简化了复杂系统的调试与监控。
- 可靠性: 消息可以被持久化存储和重试,即使系统出现故障,也能保证交互的最终一致性,提升了系统的容错能力。
优缺点
消息机制,天然支持并行发布任务给所有Agent
消息机制,可视化好,便于留记录
通信开销,分布式的消息传递机制导致会有网络延迟
消耗多,每次对话都有详细提示词、多次通信,token消耗快
CAMEL
与 AutoGen 和 AgentScope 这样功能全面的框架不同,CAMEL最初的核心目标是探索如何在最少的人类干预下,让两个智能体通过“角色扮演”自主协作解决复杂任务。
CAMEL 实现自主协作的基石是两大核心概念:角色扮演 (Role-Playing) 和 **引导性提示 (Inception Prompting)**。
引导性提示:
- 明确自身角色
- 告知协作者角色
- 定义共同目标
- 设定行为约束和沟通协议:这是最关键的一环。例如,指令会要求 AI 用户“一次只提出一个清晰、具体的步骤”,并要求 AI 助理“在完成上一步之前不要追问更多细节”,同时规定双方需在回复的末尾使用特定标志(如
<SOLUTION>)来标识任务的完成。
优缺点
轻架构、重提示(代码设计少)
多模态工具支持
高度依赖提示工程
不善于搭建大规模多智能体工程
LangGraph
思路&架构
LangGraph 将智能体的执行流程建模为一种状态机(State Machine),并将其表示为有向图(Directed Graph)。在这种范式中,图的节点(Nodes)代表一个具体的计算步骤(如调用 LLM、执行工具),而 边(Edges)则定义了从一个节点到另一个节点的跳转逻辑。
状态节点:
1 | # 定义全局状态的数据结构 |
有无条件边,这边举例一个有条件边:
1 | # 添加条件边,实现动态路由 |
优缺点
代码架构,高度可控。
使用状态机图,可预测、可设置路径,对于需要严格按照串行实现的工作(比如审计)会非常适合。
对于**循环(Cycles)**有原生支持,比如可以通过条件边来构建“反思-修正”循环。
需要事先写好结点,可控但缺少涌现式的交互,就是不太柔软。
某个结点数据出错误时会造成全部出错。
Hello Agent框架
架构
1 | hello-agents/ |
自动检测供应商
- 最优先:框架会依次检查
MODELSCOPE_API_KEY,OPENAI_API_KEY,ZHIPU_API_KEY等环境变量是否存在。一旦发现任何一个,就会立即确定对应的服务商。 - 次优先:如果用户没有设置特定服务商的密钥,但设置了通用的
LLM_BASE_URL,框架会转而解析这个 URL。 - 辅助判断:如果上述两种方式都无法确定,框架会尝试分析通用环境变量
LLM_API_KEY的格式。
框架接口
Message类
类似于阿里的AgentScope框架,也做了Msg来进行通讯,其实就是封装下role和content,然后加了个stamp时间戳。
核心还是要理解OpenAI的API标准是:{ role:str, content:str }
Config类
把全局静态变量(比如环境变量)那些全部扔到里面统一管理。
Agent抽象基类
- 构建函数里把核心都带进来:名称、LLM 实例、系统提示词和配置
- 强制要求实现run方法
- 历史记录
history的初始化,以及一些基础方法:clear、append、copy
自定义的Agent类
继承抽象Agent基类后,在run方法里实现
- 历史消息添加
- while循环,带着工具列表和上下文,多次调用LLM
- 在循环里,工具调用之后的结果也会加入上下文内容
- 如果已经没有工具调用了,或者 超过最大迭代次数,就代表回答结束。
- 保存上面的长串message到历史记录
工具管理类
有注册Tool功能等,本质就是个字典 + 一堆方法。
使用
可以直接用这个基础框架,优化一下prompt、实现ReAct等不同范式。
