
Hello Agents - 基础概念
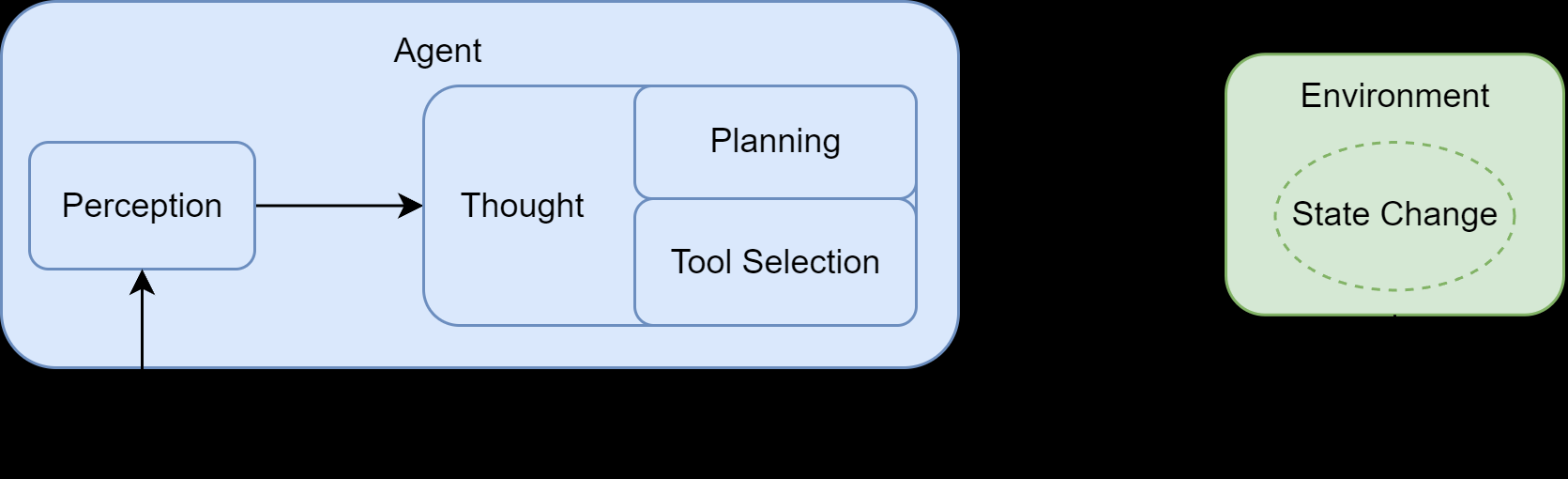
Agent构成&运行原理
PEAS

运行机制
AI模型进化路线
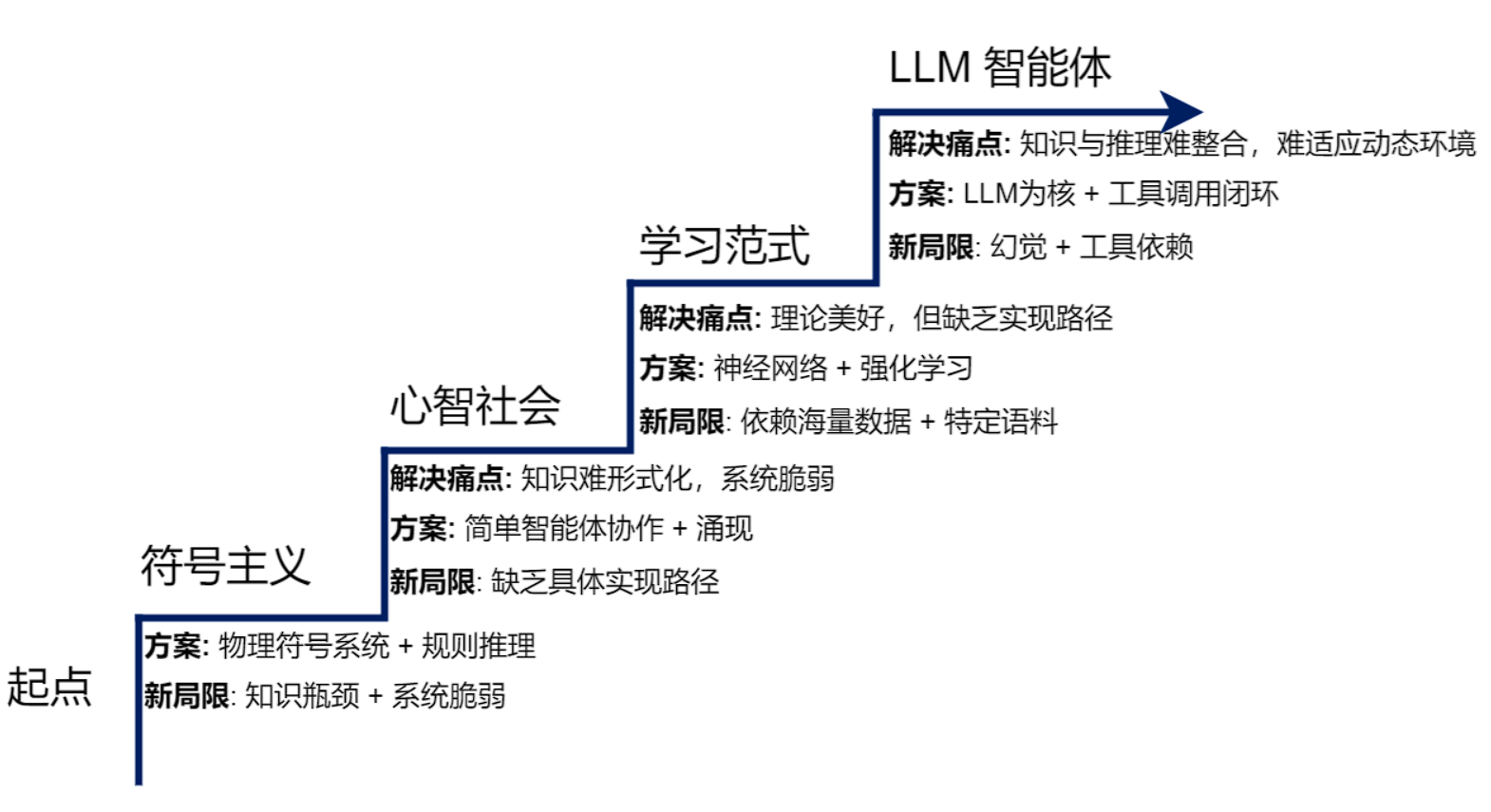
符号主义范式
知识库(规则)+ 推理机。不智能,需要人工输入规则比如 IF THEN,且比较死板导致健壮性差,诞生了“专家系统”这类产物。
联结主义范式
与符号主义自上而下、依赖明确逻辑规则的设计哲学不同,联结主义是一种自下而上的方法,其灵感来源于对生物大脑神经网络结构的模仿。做出神经元(小的功能),把他们分布式的连接起来,并通过算法学习对系统设置神经元的连接权重。这一范式能成功源于计算机已经能对图片声音文本等信息直接进行理解,反映了心智社会。
强化学习
通过给行为设置奖励权重,来让智能体在大量“试错”中有目的性的学习。通过“感知-行动-学习”的闭环中持续迭代自己,让其更有远见。
预训练
在进行强化学习等特化目标的训练前,先用自然语言处理+监督自学习,把大量的网络文本进行输入训练出一个基础的通用模型LLM,它的目的是有一些基础常识,比如“预测下一个词”。
然后再对预训练好的模型,根据具体任务要求进行微调(小样本数据标注学习),来实现目的。
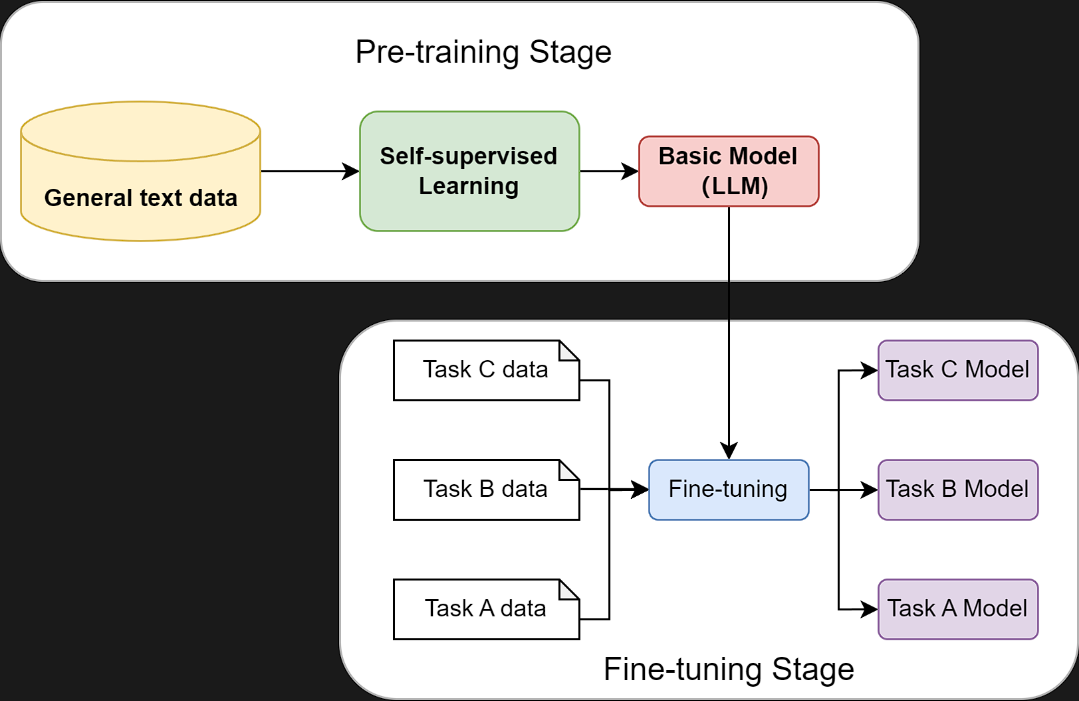
通过大量预训练的LLM,涌现出了预料外的能力:
- 上下文学习(In-context Learning):无需调整模型权重,仅在输入中提供几个示例(Few-shot)甚至零个示例(Zero-shot),模型就能理解并完成新的任务。
- 思维链(Chain-of-Thought)推理:通过引导模型在回答复杂问题前,先输出一步步的推理过程,可以显著提升其在逻辑、算术和常识推理任务上的准确性。
大模型
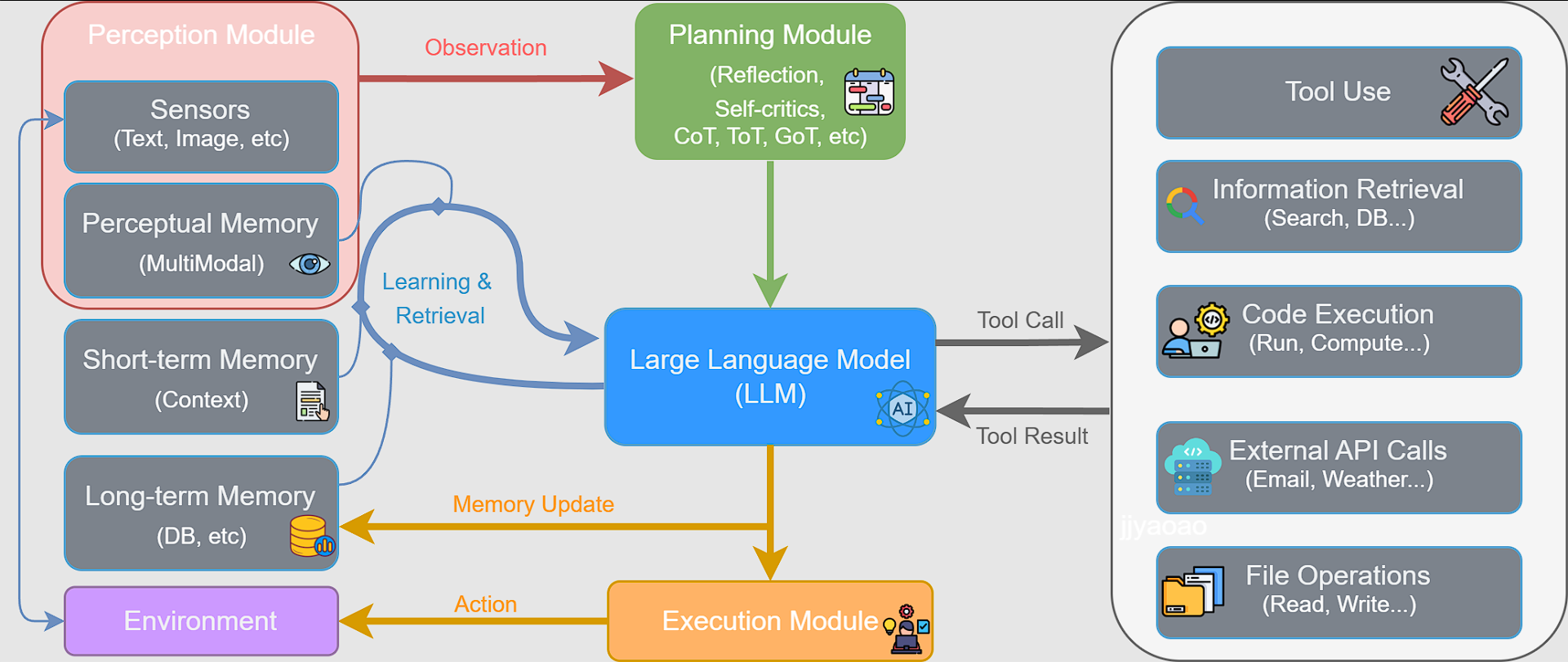
大语言模型
RNN 循环神经网络
引入多维向量概念,来表示词库,结点在空间中离得越近就代表两个词意思越接近。串行计算,单词[N]需要前面单词[0] ~ 单词[N-1]总计算下来的结果作为参数。
RNN 的设计引入了一个隐藏状态 (hidden state) 向量,我们可以将其理解为网络的短期记忆。在处理序列的每一步,网络都会读取当前的输入词,并结合它上一刻的记忆(即上一个时间步的隐藏状态),然后生成一个新的记忆(即当前时间步的隐藏状态)传递给下一刻。
因此“隐藏状态”这个记忆机制,导致计算必须串行进行,且上下文可能会很大。
Transformer
优点☆
- 比起RNN,它用Attention概念,更擅长远距离的情况
- 比起RNN,它可以并行处理计算
注意力计算(单头)
Transformer在2017 年由谷歌团队提出。它完全抛弃了循环结构,转而完全依赖一种名为注意力 (Attention) 的机制来捕捉序列内的依赖关系,从而实现了真正意义上的并行计算。
- **查询 (Query, Q)**:代表当前词元,它正在主动地“查询”其他词元以获取信息。
- **键 (Key, K)**:代表句子中可被查询的词元“标签”或“索引”。
- **值 (Value, V)**:代表词元本身所携带的“内容”或“信息”
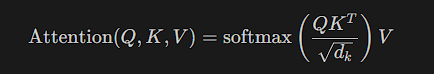
简单理解:
每个词都有 QKV三个值,Q=我要问什么,K=我的标签,V=我的信息。对每个词,都带Q去匹配其他词的K,来得出需要对其他词分配多少的Attention权重。最后再用权重乘一下每个词的V,来求得这个词的问题结果。
因此,每个词都是独立和整个句子进行匹配的,完全可以并行计算;而注意力机制本身并没有涉及到顺序概念,不像RNN那样串行直接带了顺序,因此又引入位置编码概念来解决这个问题。
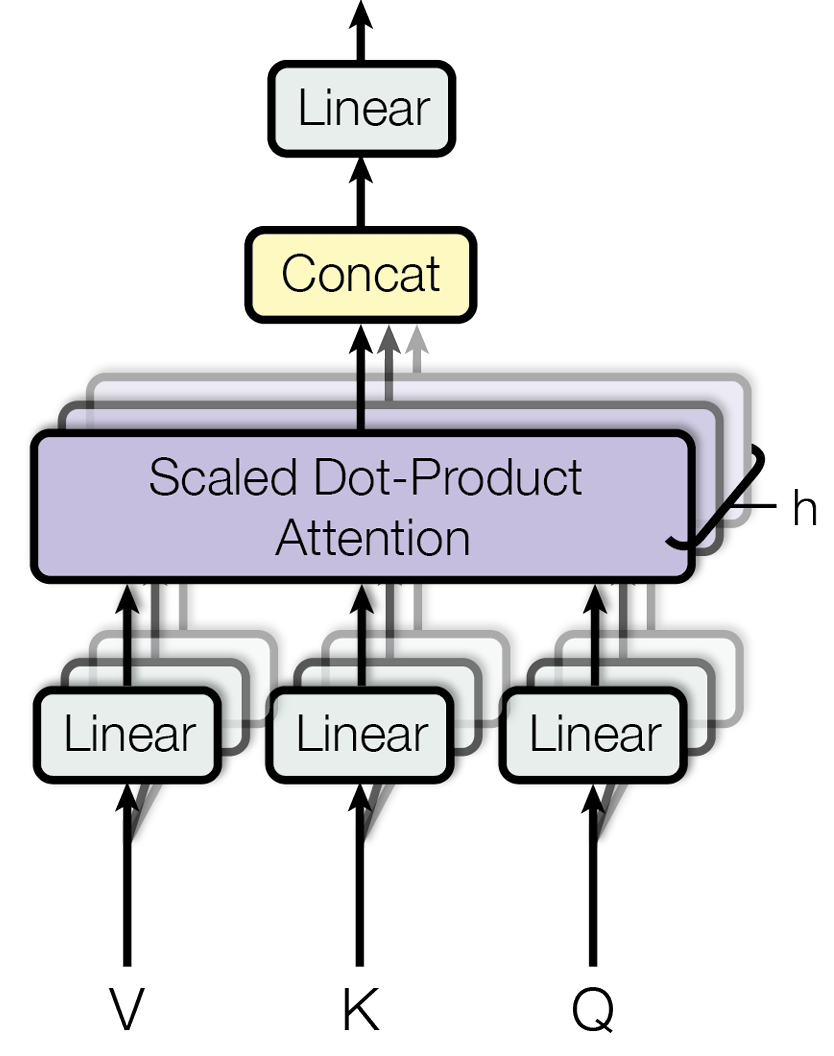
多头
它将原始的 Q, K, V 向量在维度上切分成 h 份(h 就是“头”数),每一份都独立地进行一次单头注意力的计算。这就好比让 h 个不同的“专家”从不同的角度去审视句子,每个专家都能捕捉到一种不同的特征关系。最后,将这 h 个专家的“意见”(即输出向量)拼接起来,再通过一个线性变换进行整合,就得到了最终的输出。
Decoder-Only
放弃了编码器只保留解码器,只关心“预测下一个词”这件事。
优势:训练目标统一、结构简单易于扩展、天然适合生成任务。
模型采样
- Tempurature = 胆大程度,为0时候极度保守只选top1,0-1时比较保守,1以上越大越发散
- Top-k = token从高到低排,取前k个
- Top-p = token从高到低排,算token的概率,累加概率,大于等于p结束。
BPE分割词
- 对每个词都所有在语料库中出现过的基本字符。
- 迭代合并:在语料库上,统计所有相邻词元对的出现频率,找到频率最高的一对,将它们合并成一个新的词元,并加入词表。
- 重复:重复第 2 步,直到词表大小达到预设的阈值。

模型幻觉
模型幻觉(Hallucination)通常指的是大语言模型生成的内容与客观事实、用户输入或上下文信息相矛盾,或者生成了不存在的事实、实体或事件。幻觉的本质是模型在生成过程中,过度自信地“编造”了信息,而非准确地检索或推理。
解决方案:
数据层面: 通过高质量数据清洗、引入事实性知识以及强化学习与人类反馈 (RLHF) 等方式,从源头减少幻觉。
模型层面: 探索新的模型架构,或让模型能够表达其对生成内容的不确定性。
推理与生成层面:
- 检索增强生成 (Retrieval-Augmented Generation, RAG) : 这是目前缓解幻觉的有效方法之一。RAG 系统通过在生成之前从外部知识库(如文档数据库、网页)中检索相关信息,然后将检索到的信息作为上下文,引导模型生成基于事实的回答。
- 多步推理与验证: 引导模型进行多步推理,并在每一步进行自我检查或外部验证。
- 引入外部工具: 允许模型调用外部工具(如搜索引擎、计算器、代码解释器)来获取实时信息或进行精确计算。
